Begin exploring your analysis today! Now available to all NanoString users.
Register for sponsored access to receive nCounter data analysis for 1 year.
 Learn More
Learn More
If you are a scientist analyzing nCounter data, ROSALIND enables same day analysis results with a rich engaging user experience that saves valuable time and restores the thrill of discovery.
Learn More
If you are a scientist analysing nCounter data, ROSALIND enables same day analysis results with a rich engaging user experience that saves valuable time and restores the thrill of discovery.
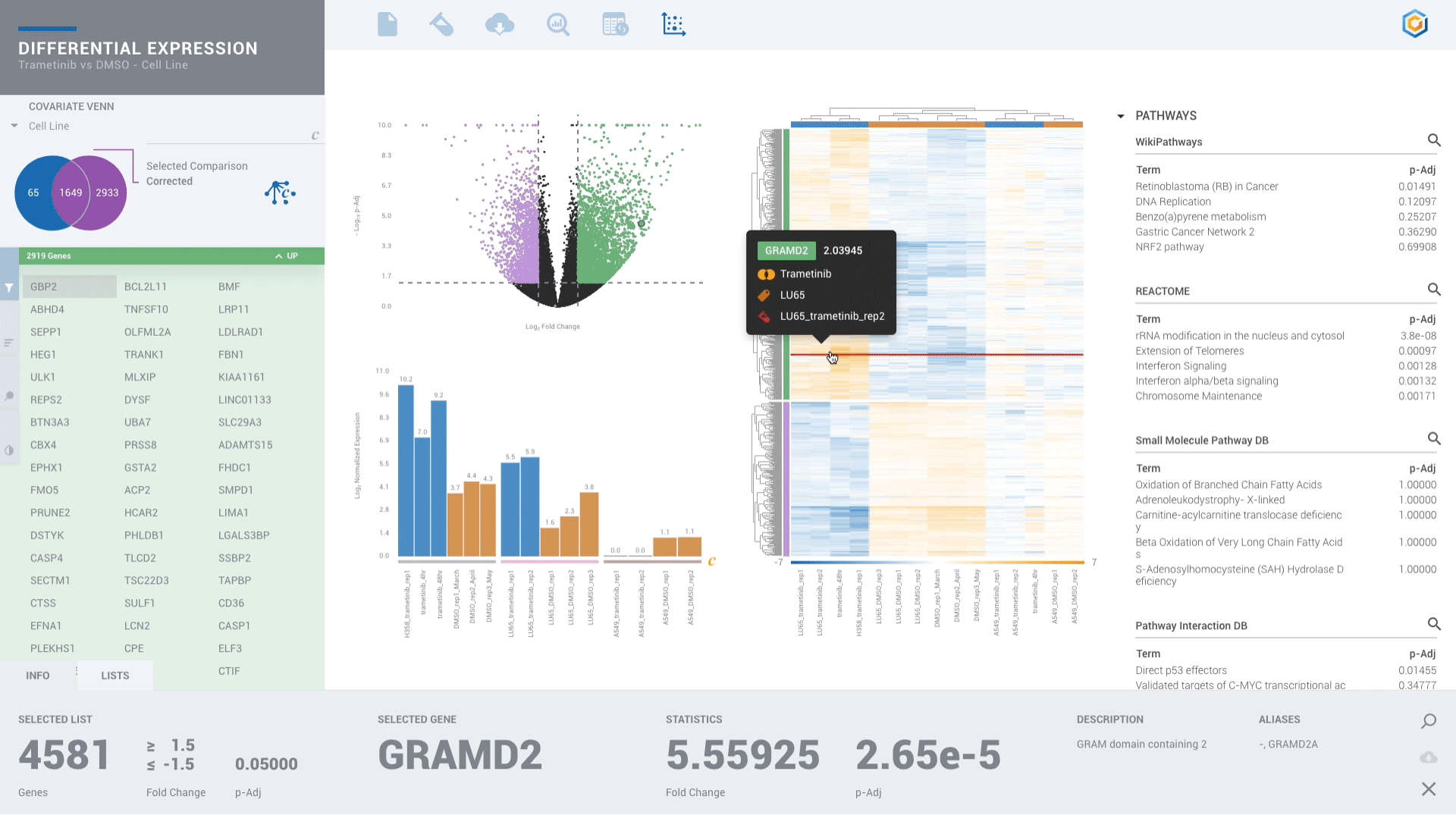
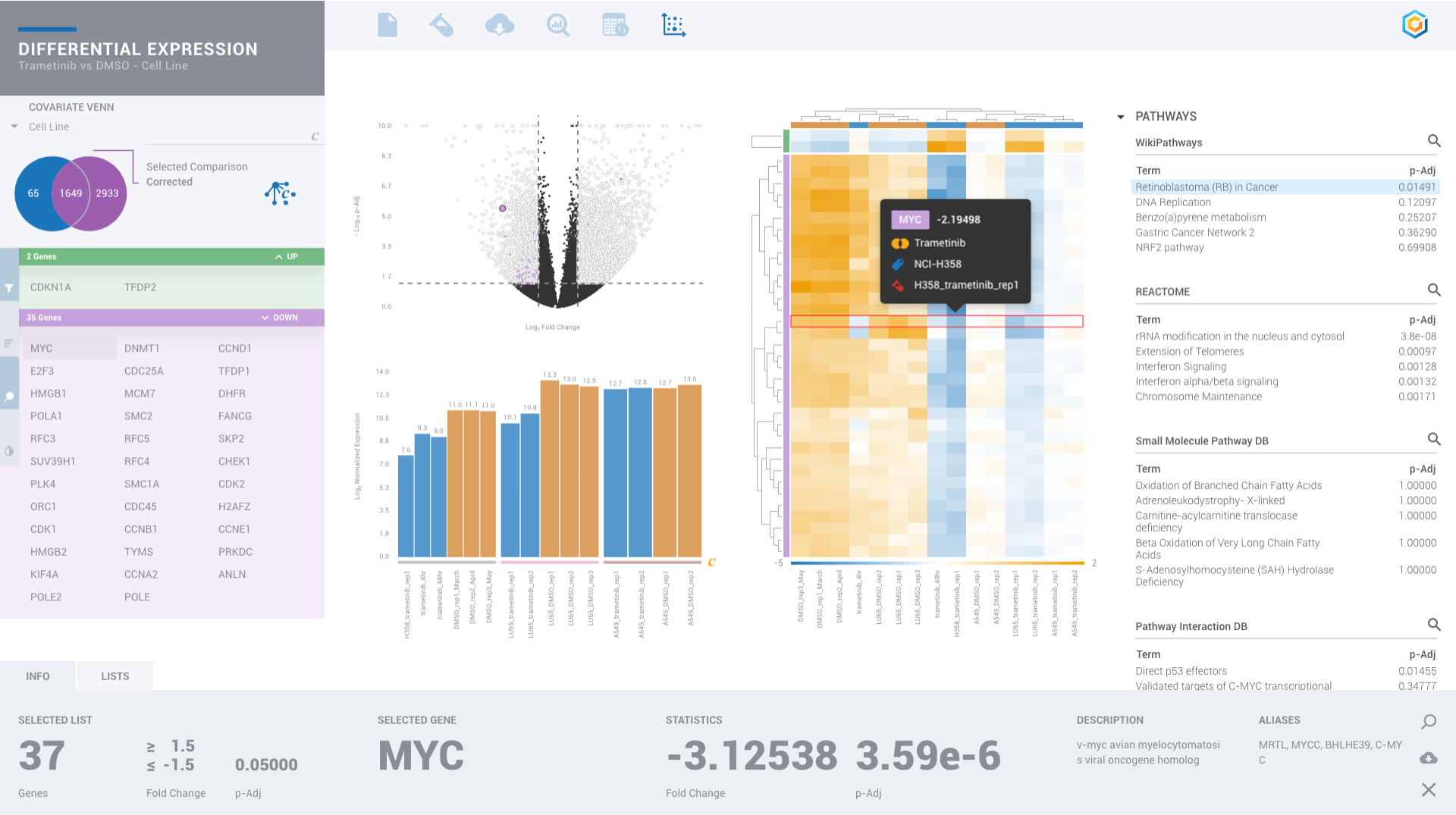
Scientists of every skill level can benefit from ROSALIND since no programming or bioinformatics skills are required. With powerful downstream analysis and collaboration, ROSALIND is a discovery platform and data hub connecting experiment design, quality control and pathway exploration.
ROSALIND automatically manages tens of thousands of compute cores and petabytes of storage to dynamically scale up and down for every experiment to deliver results.
Instantly share results with other scientists across the globe with audit tracking so everyone can focus on the interpretation not the processing.
Interconnect every stage of NGS data analysis to discover more than ever thought possible with collections of fragmented applications and tools.
Every scientist should have the freedom to perform advanced analyses without the dependence or delay of waiting on someone else to analyze their own data and miss what they know is there. Enjoy more than 50 knowledge bases all in one platform.
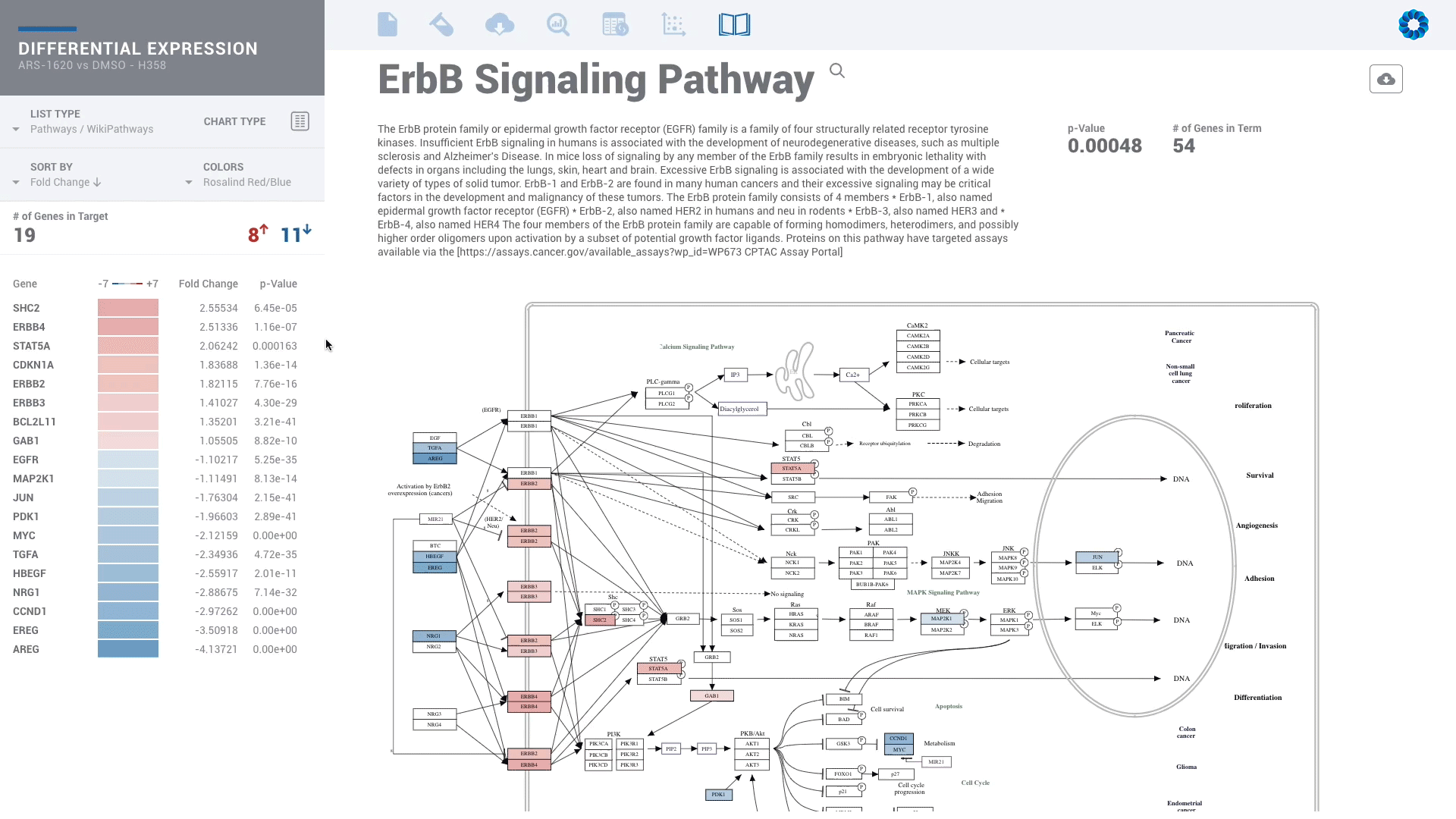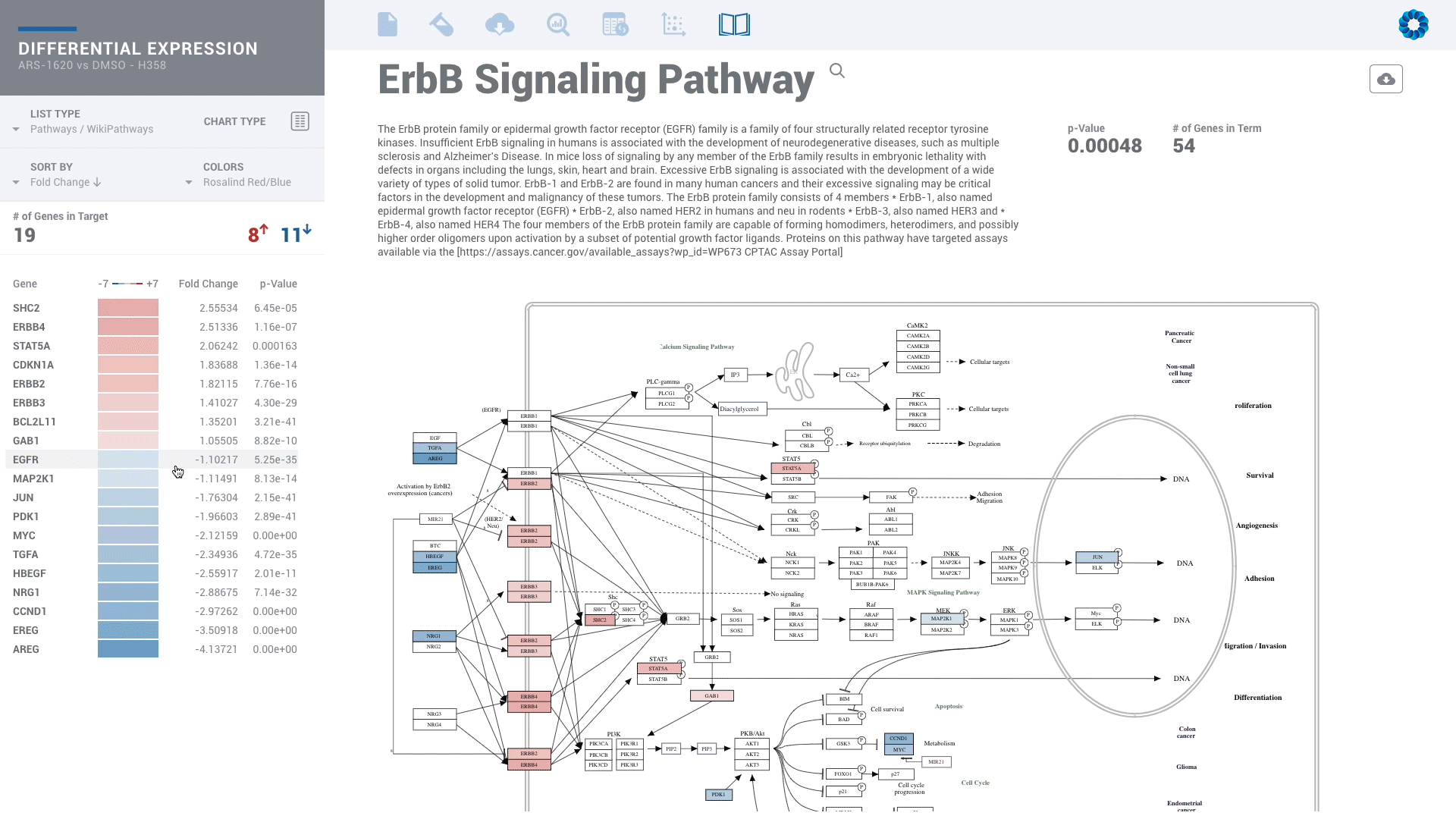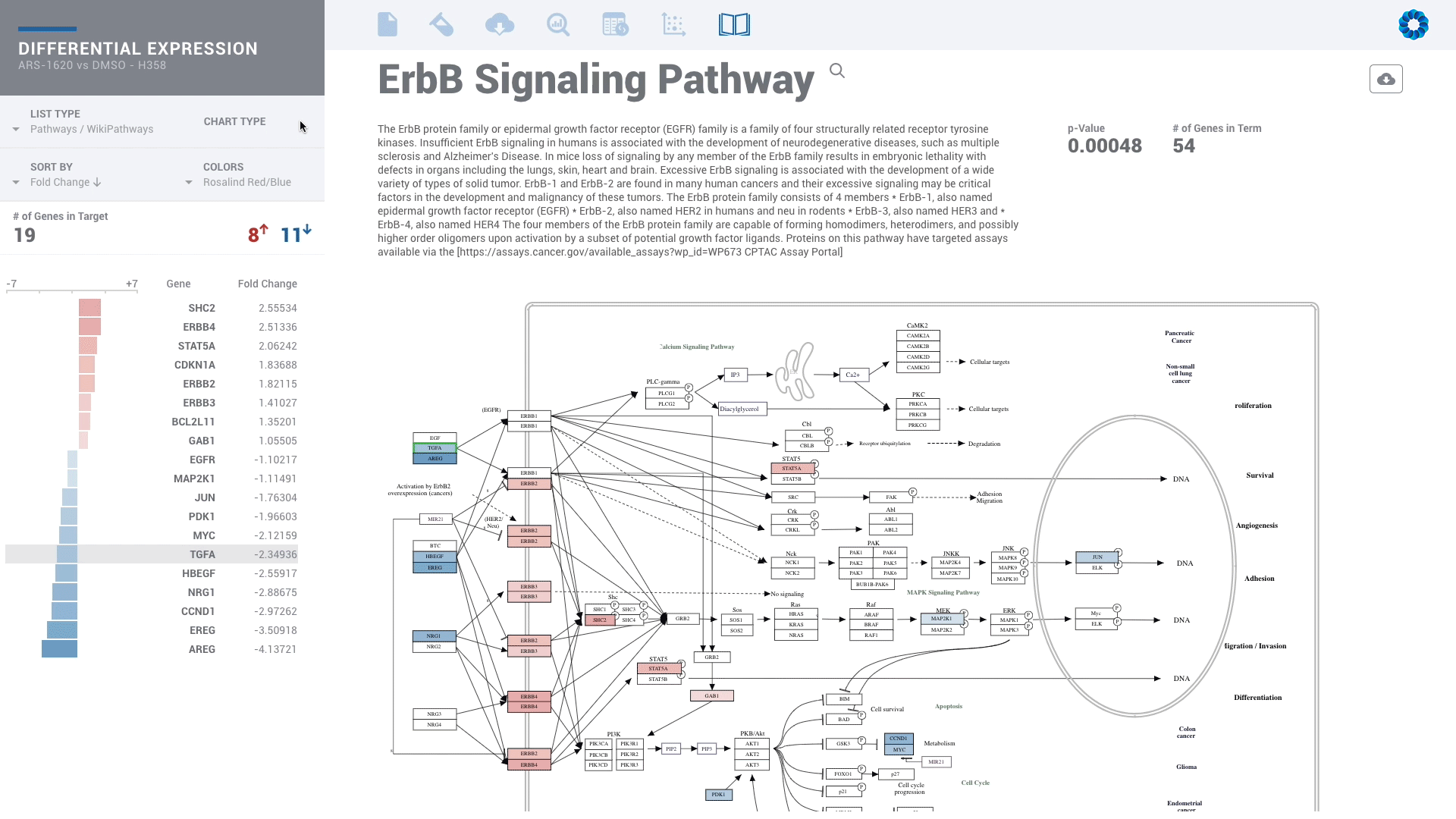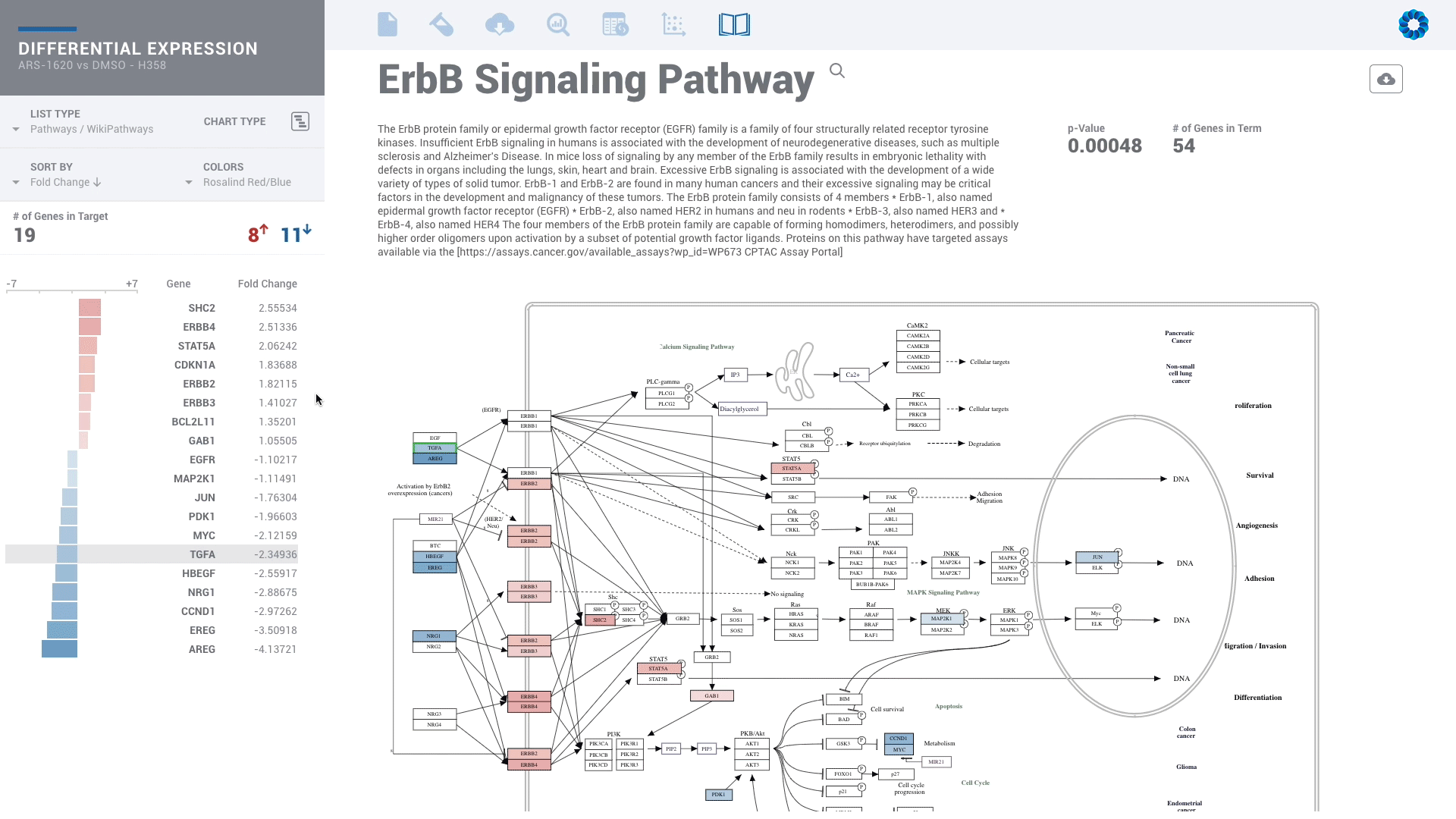
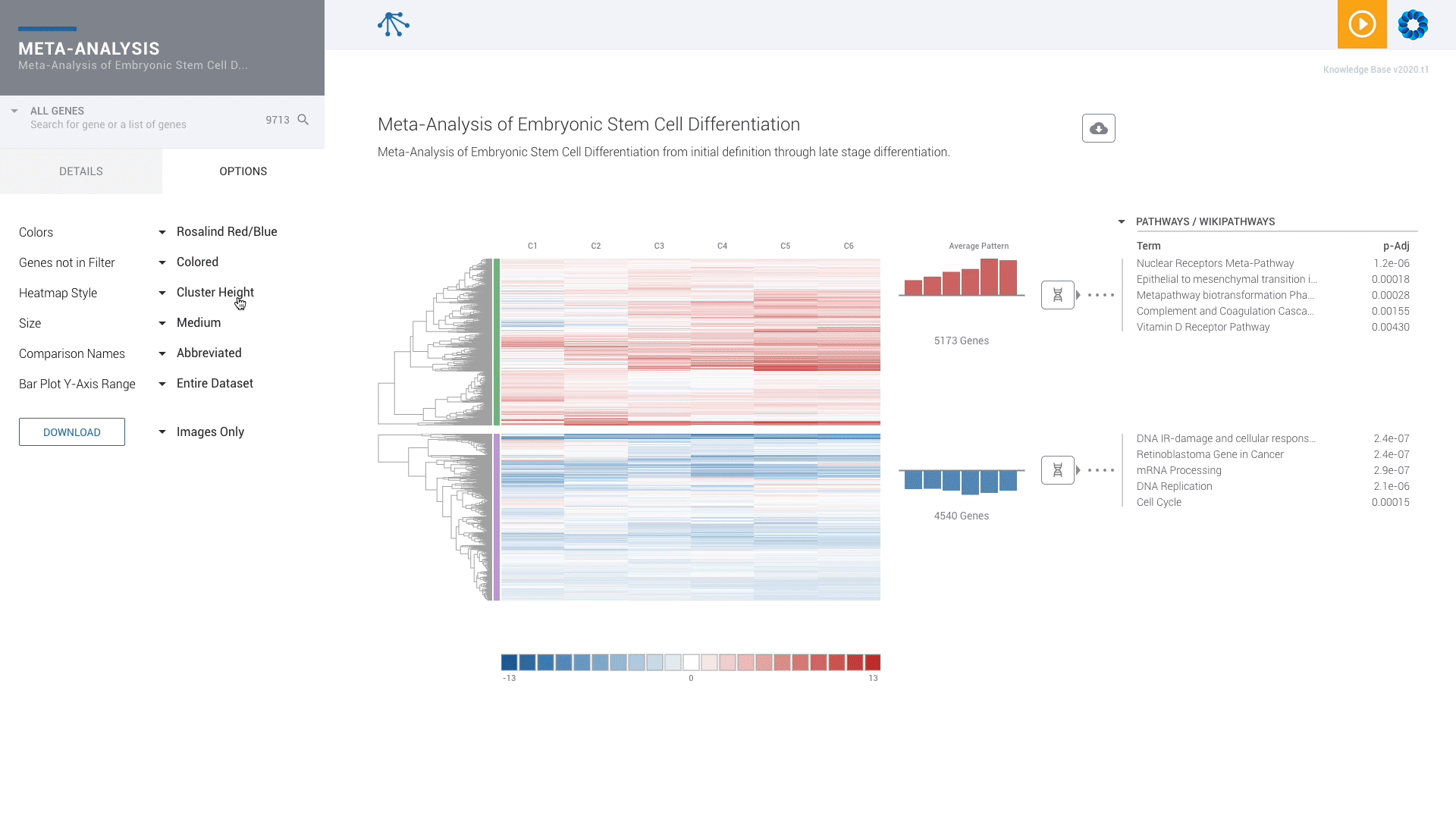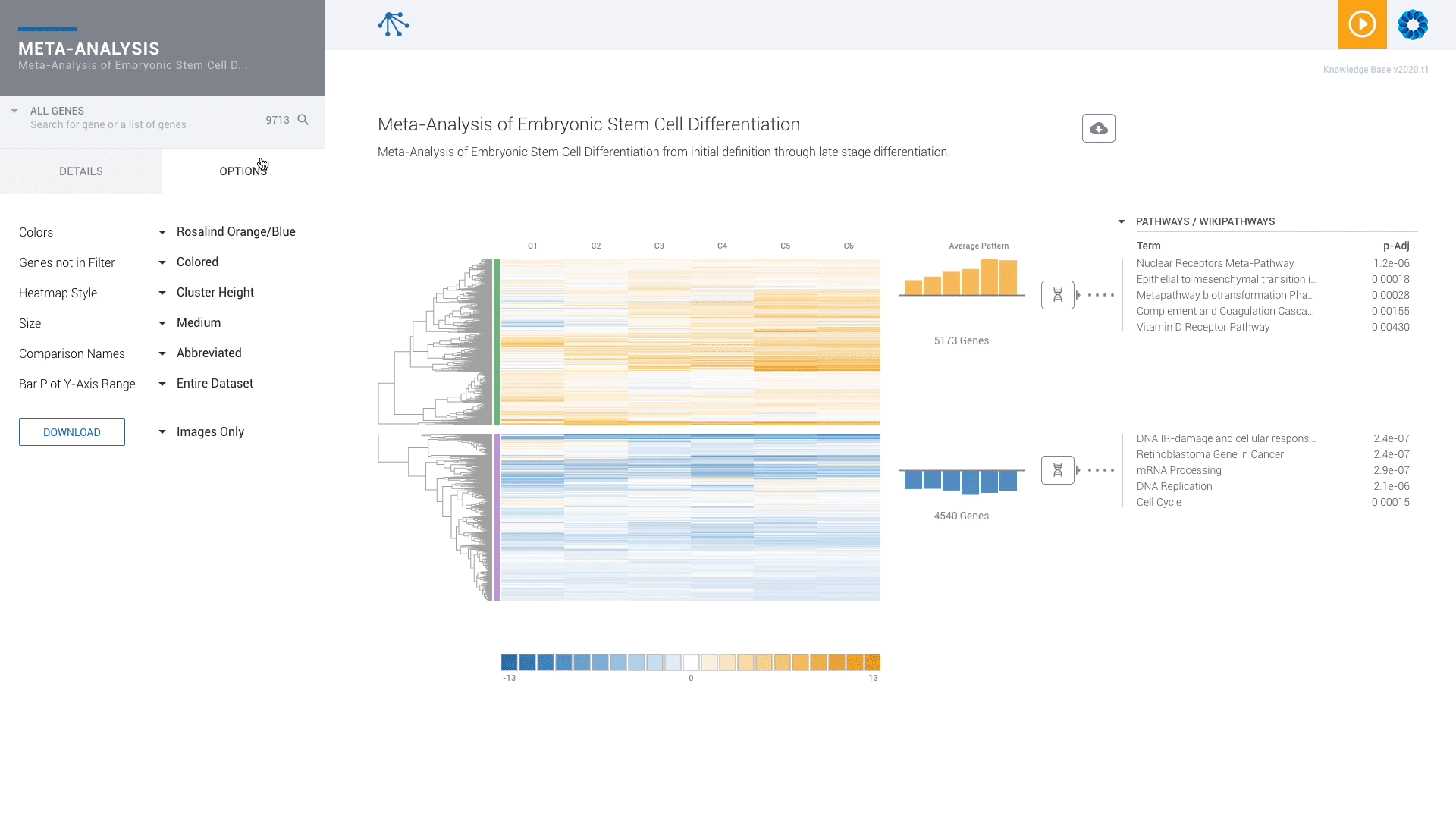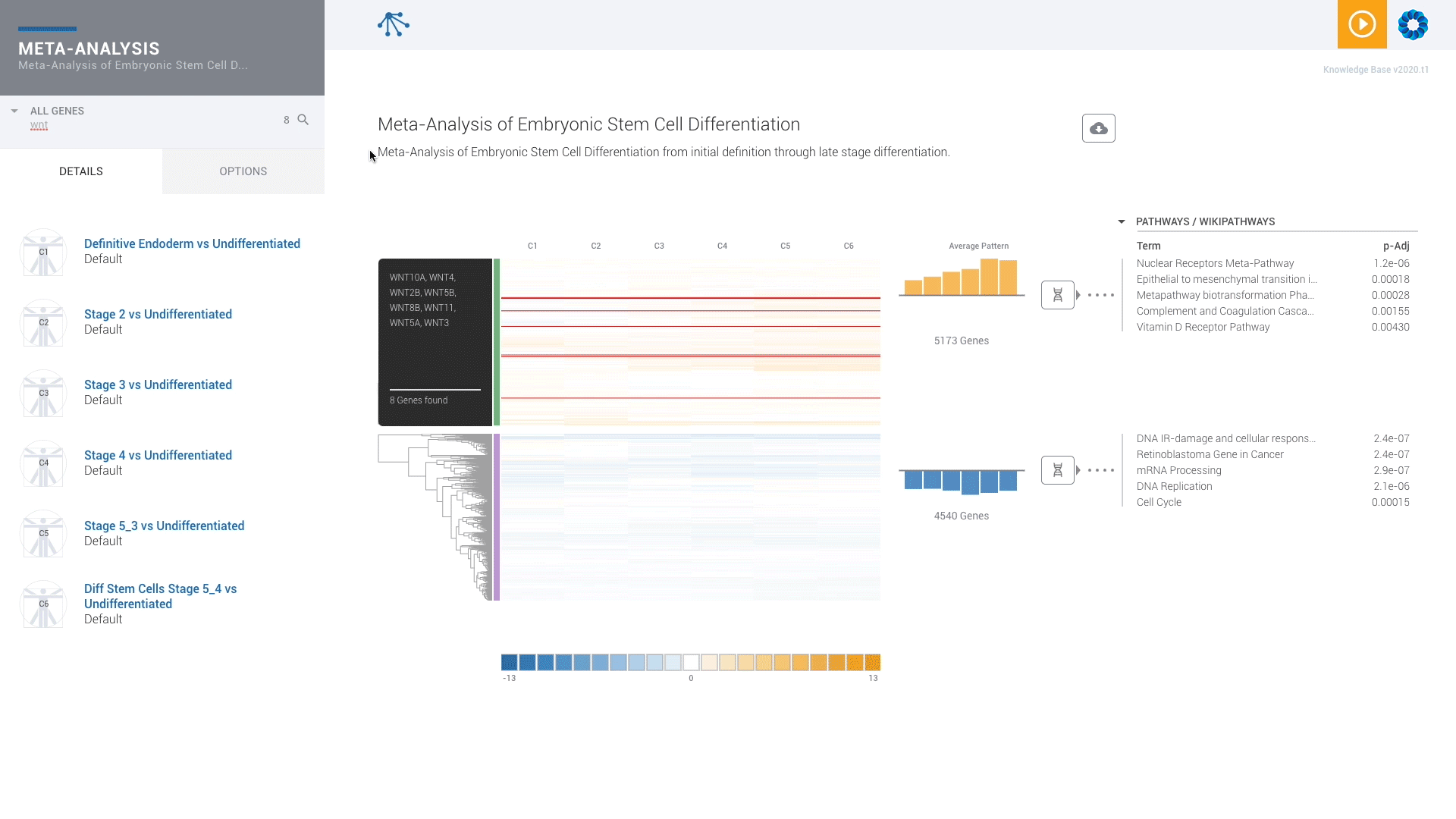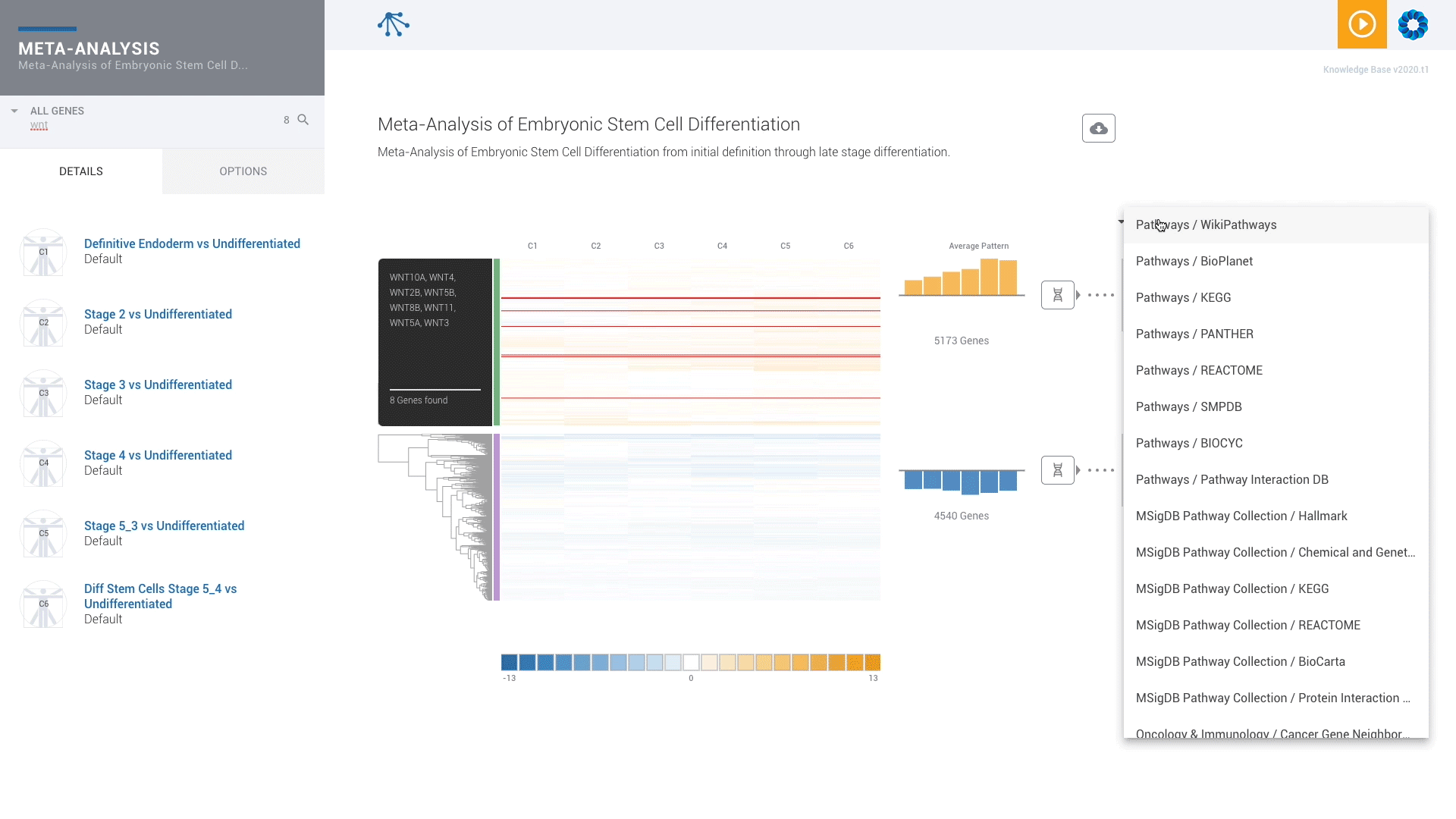
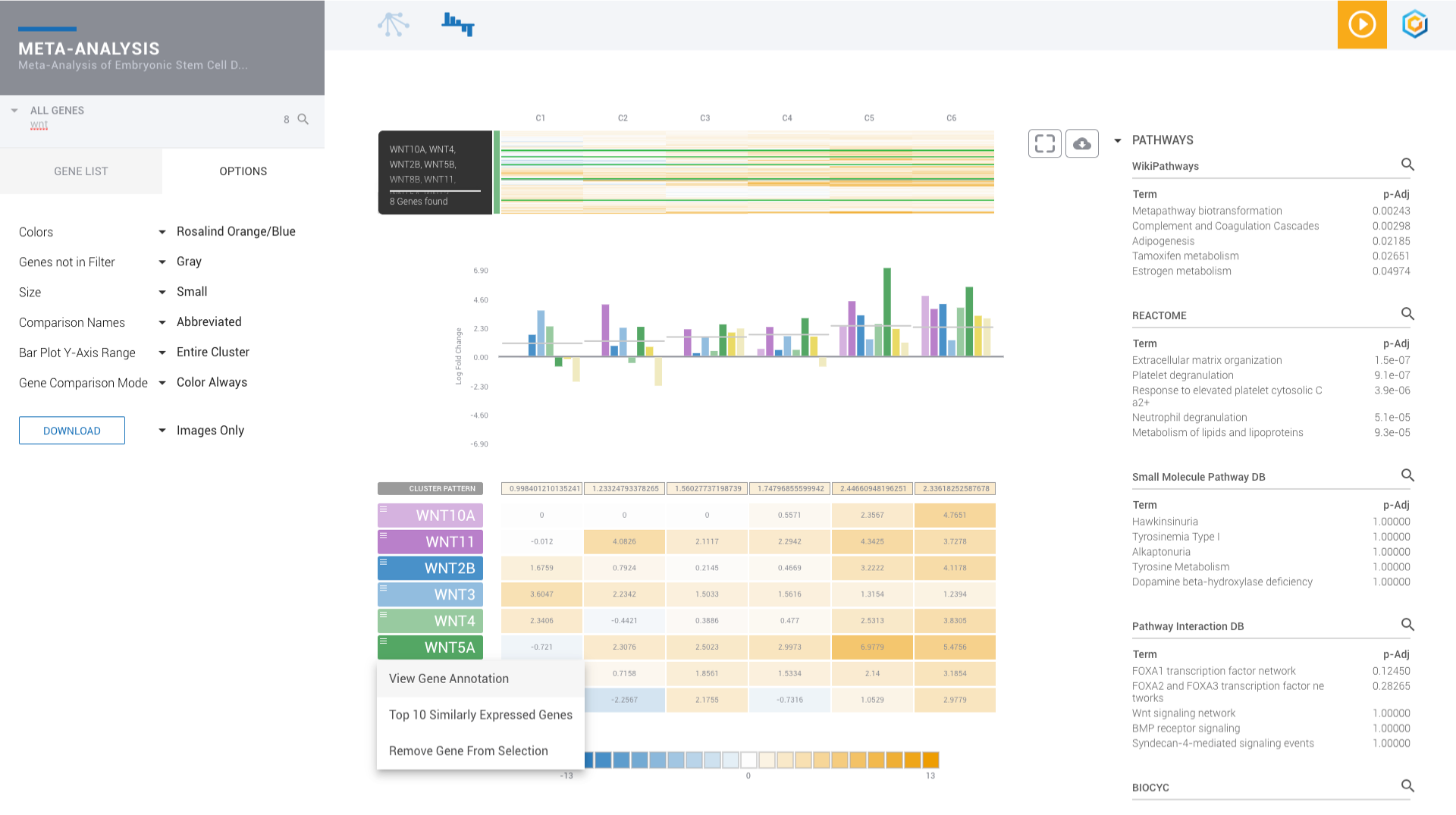
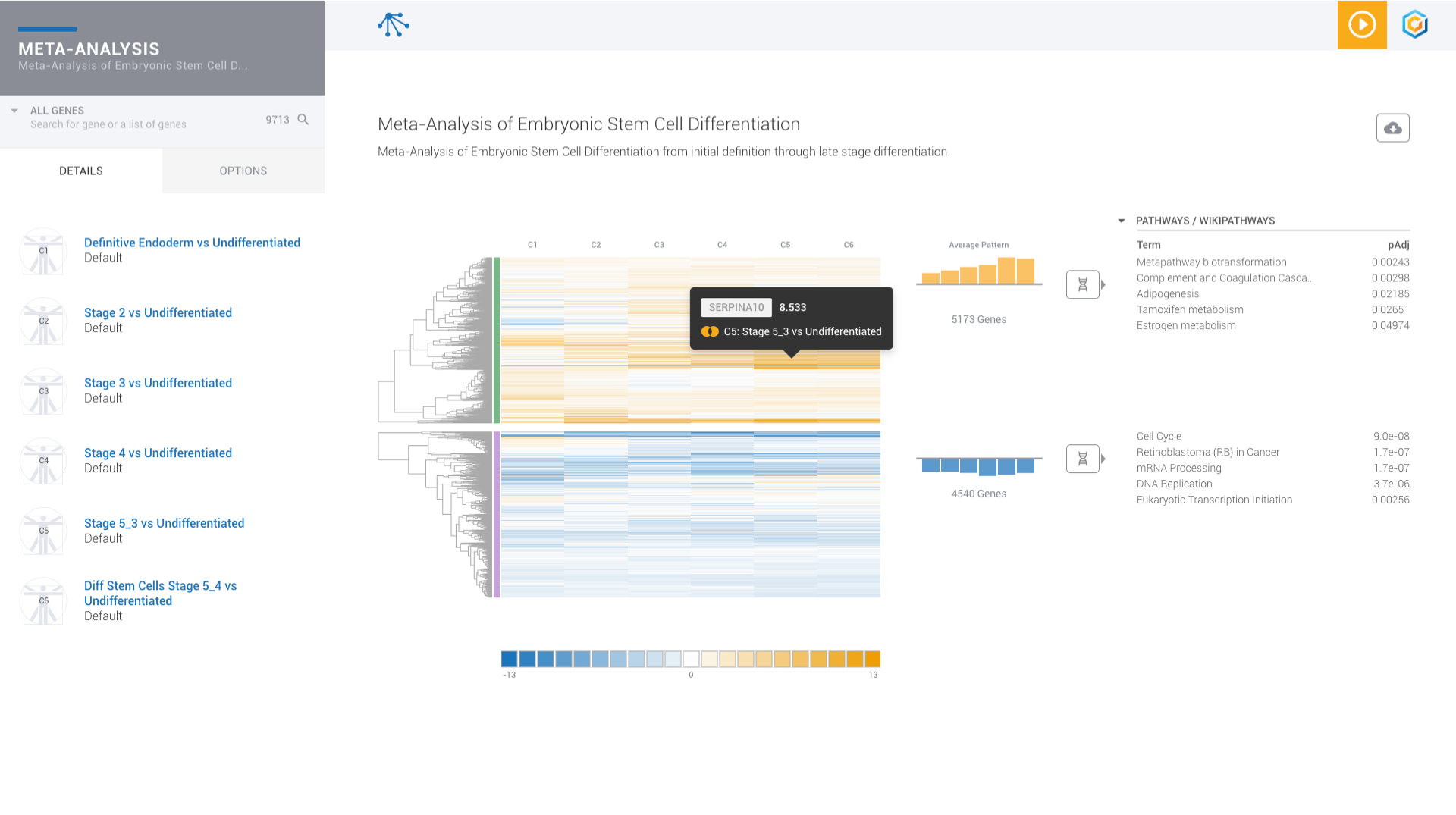
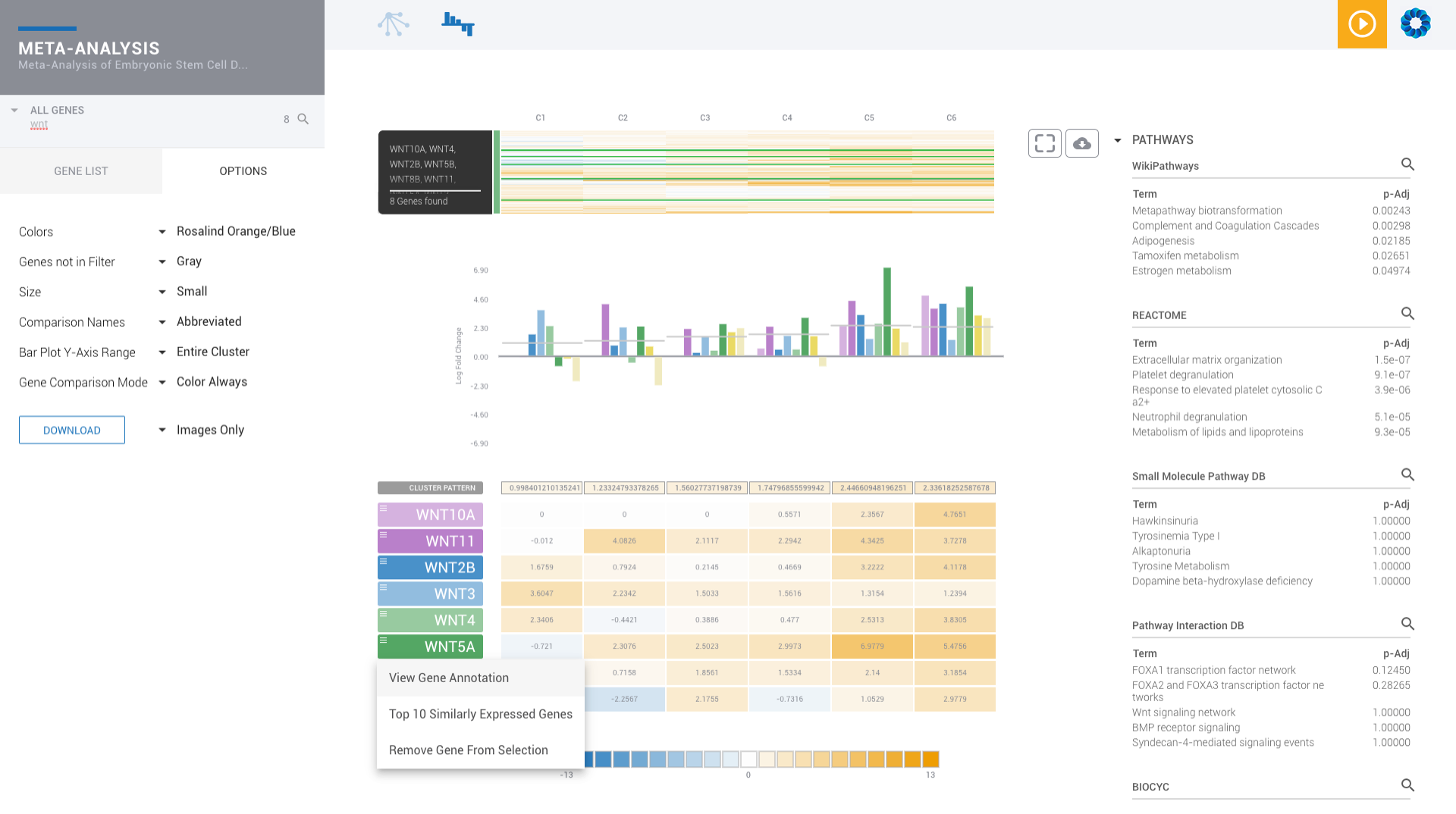
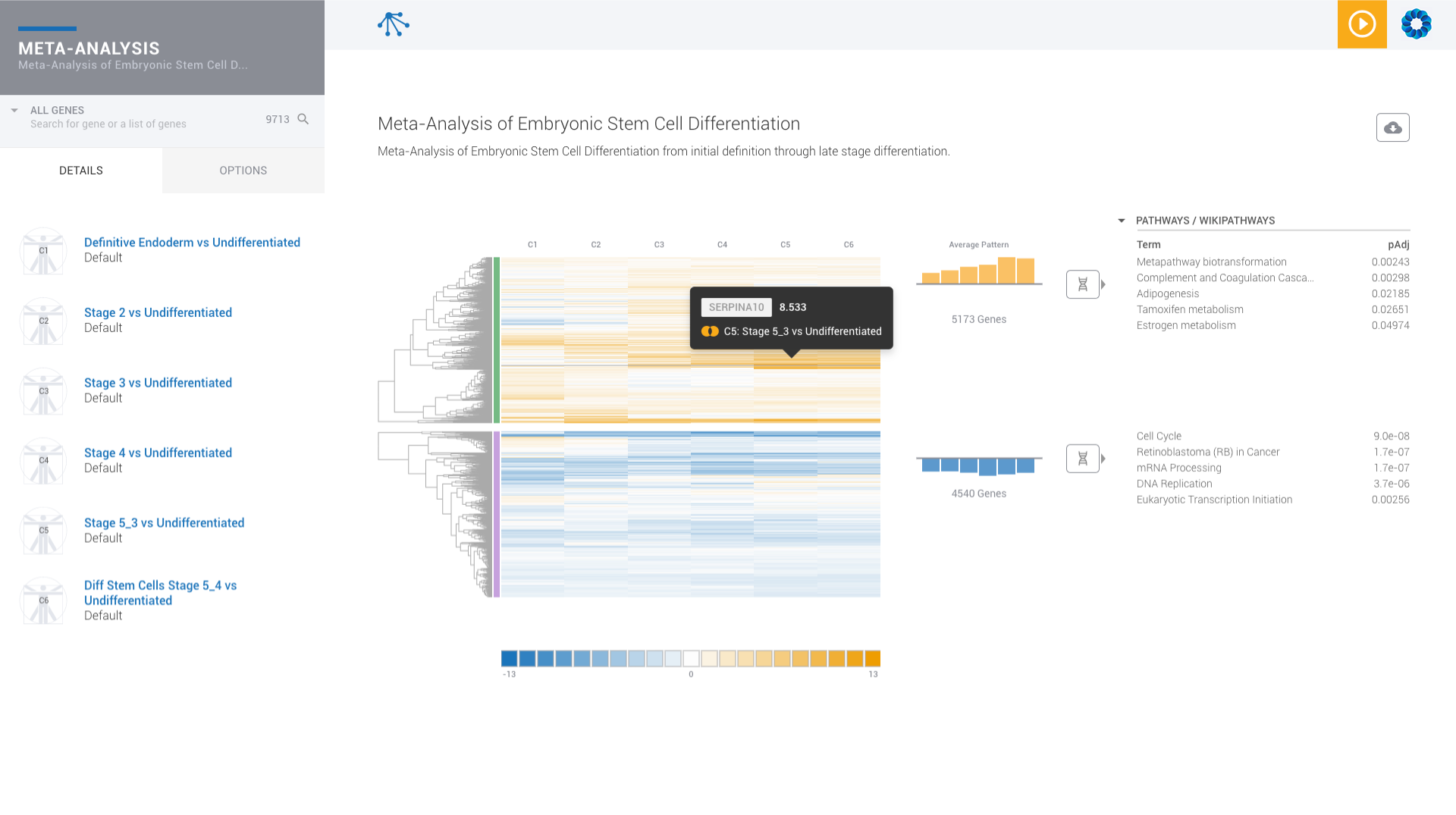
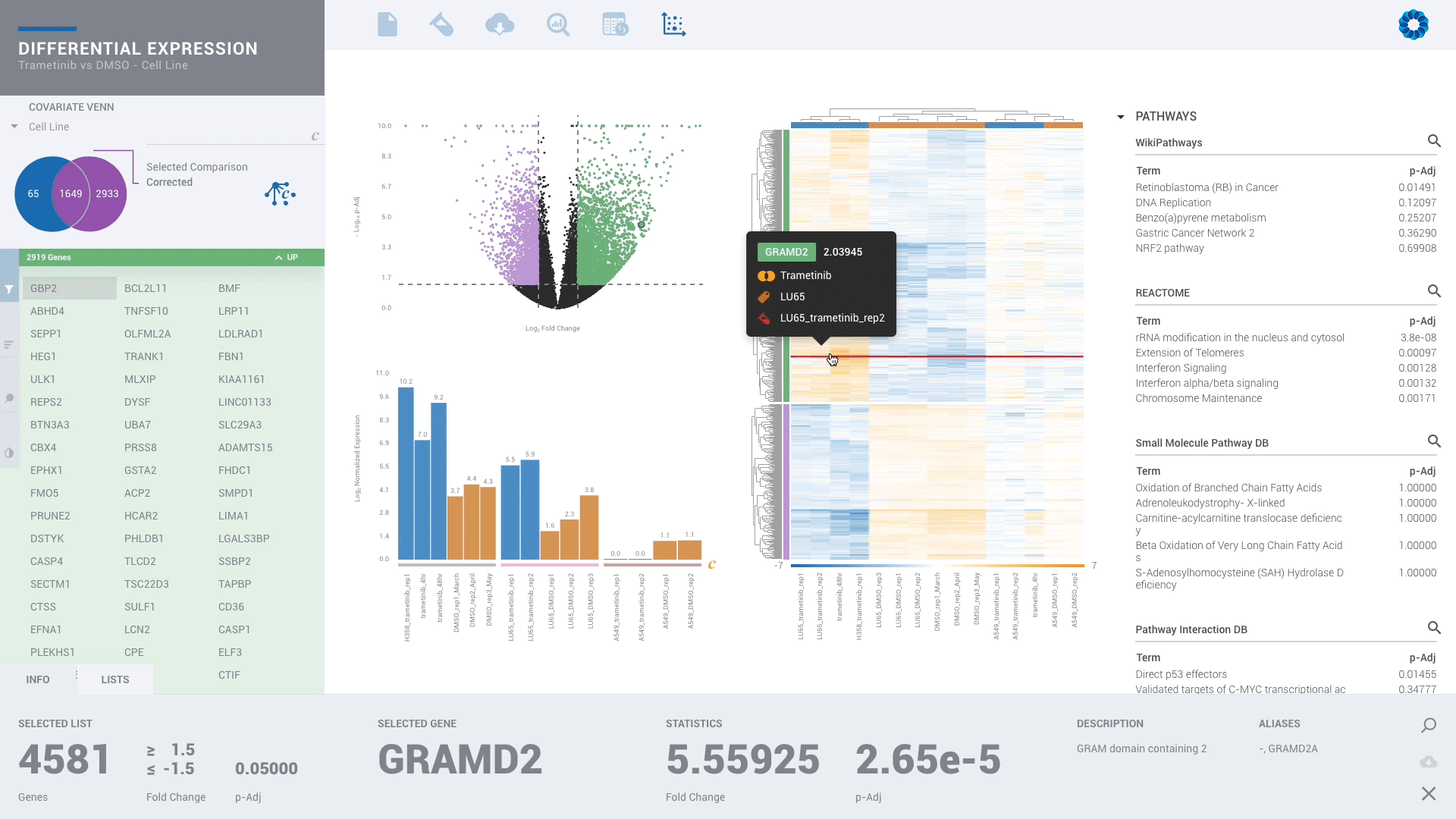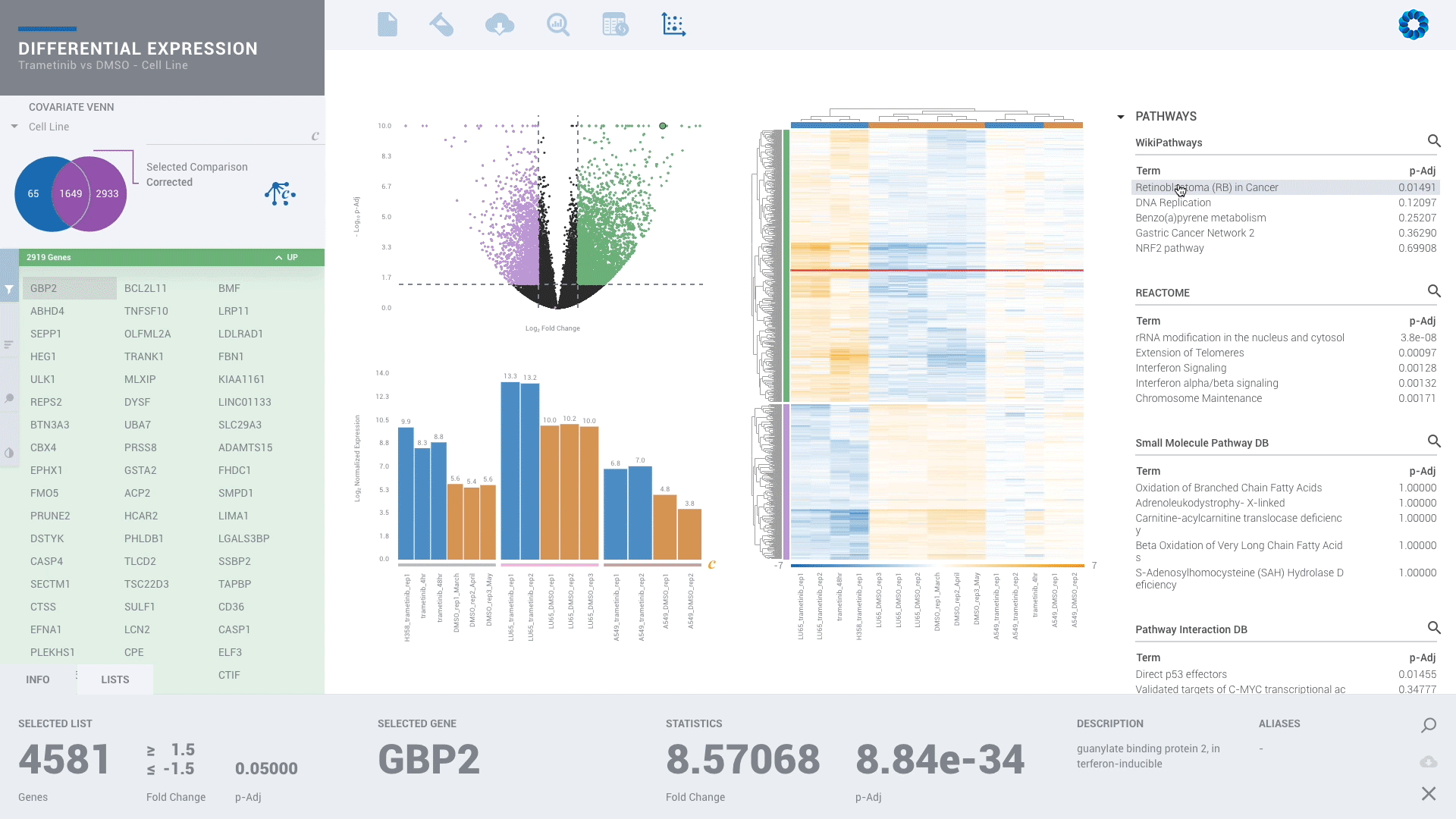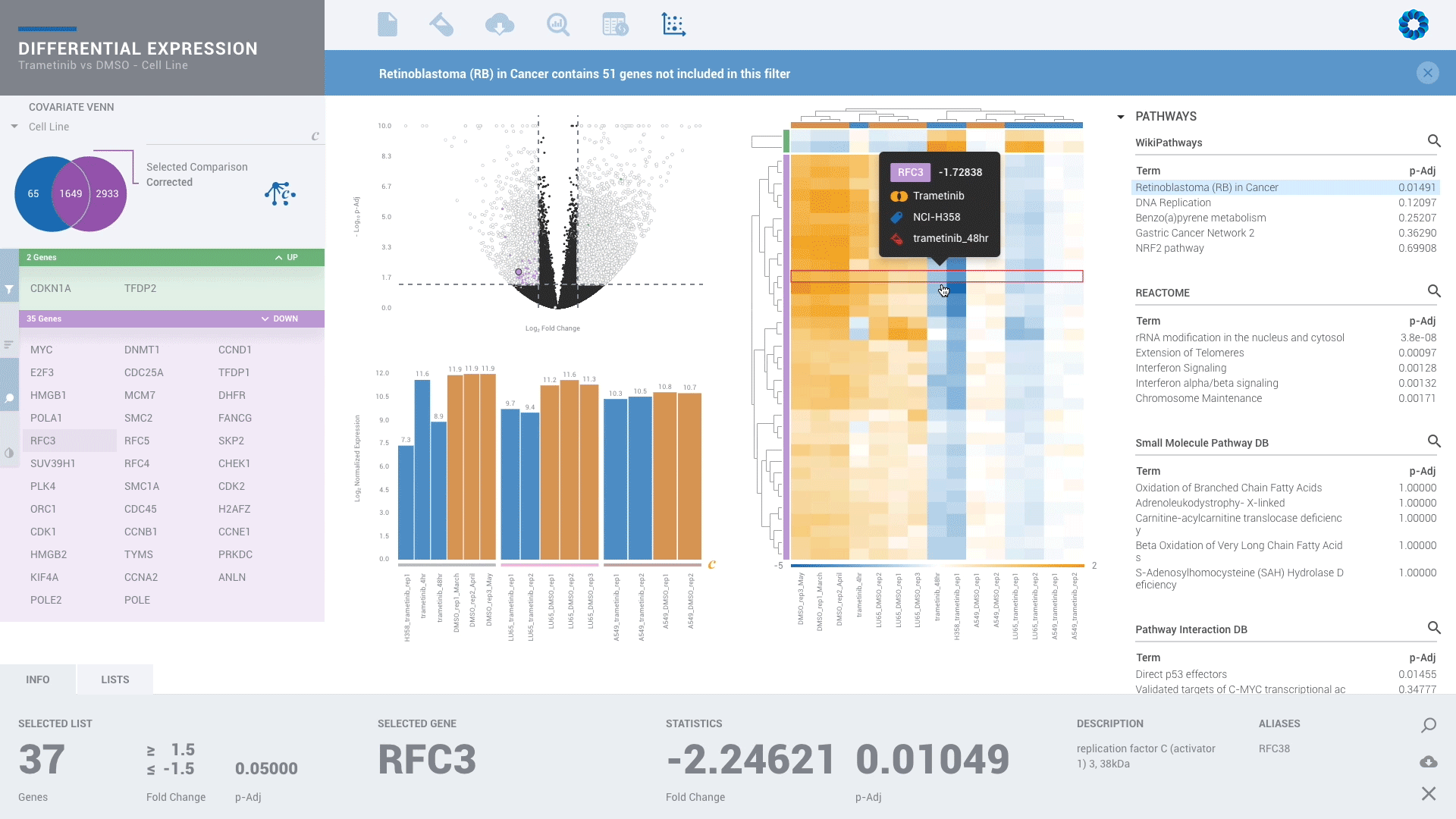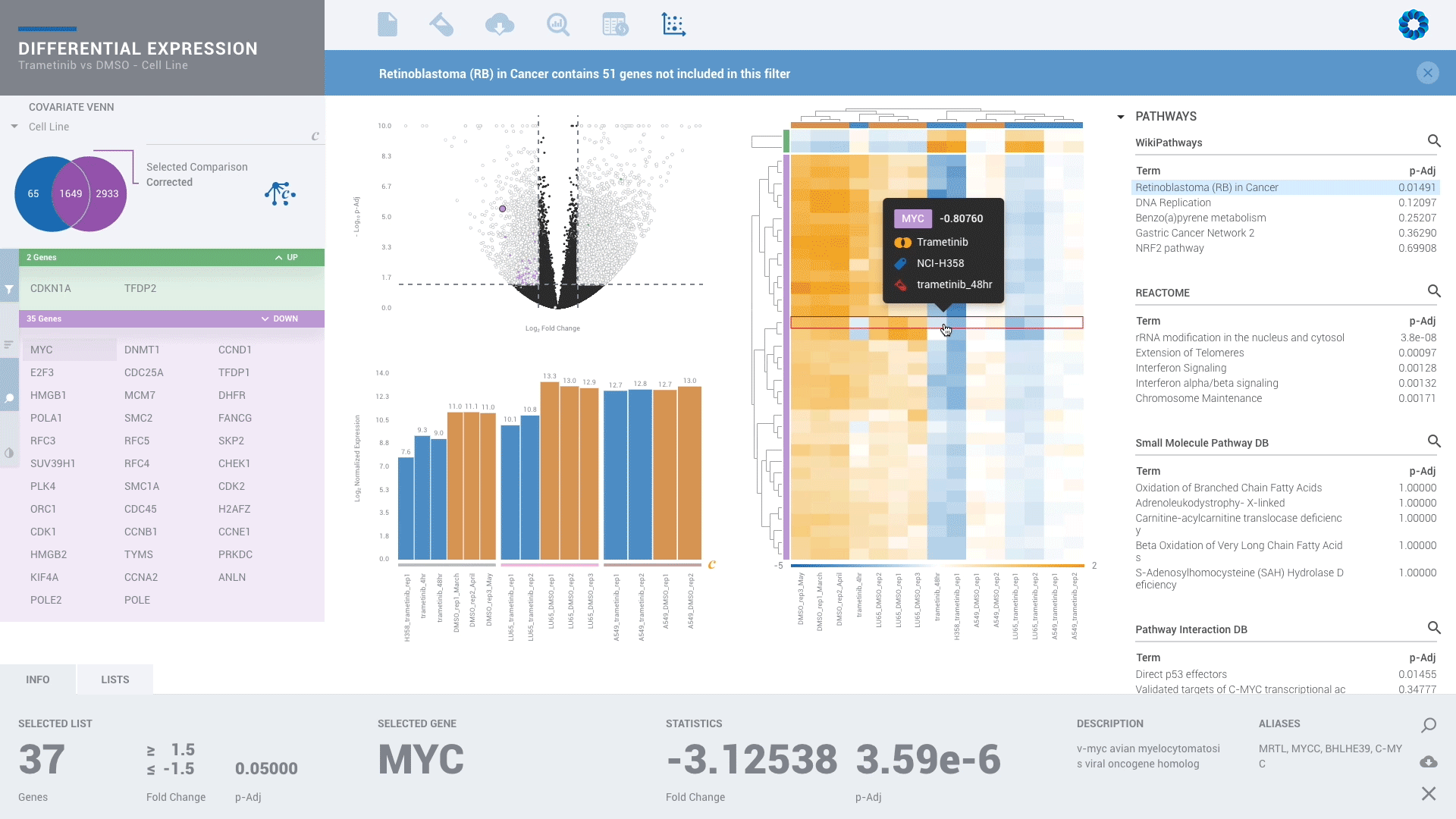
Find patterns across comparisons with advanced machine learning in Meta-Analysis.
Now you can easily process nCounter RCC files taken directly from the nCounter Digital Analyzer, or export a collection of experiments from nSolver to jumpstart your research and begin your visual discovery.
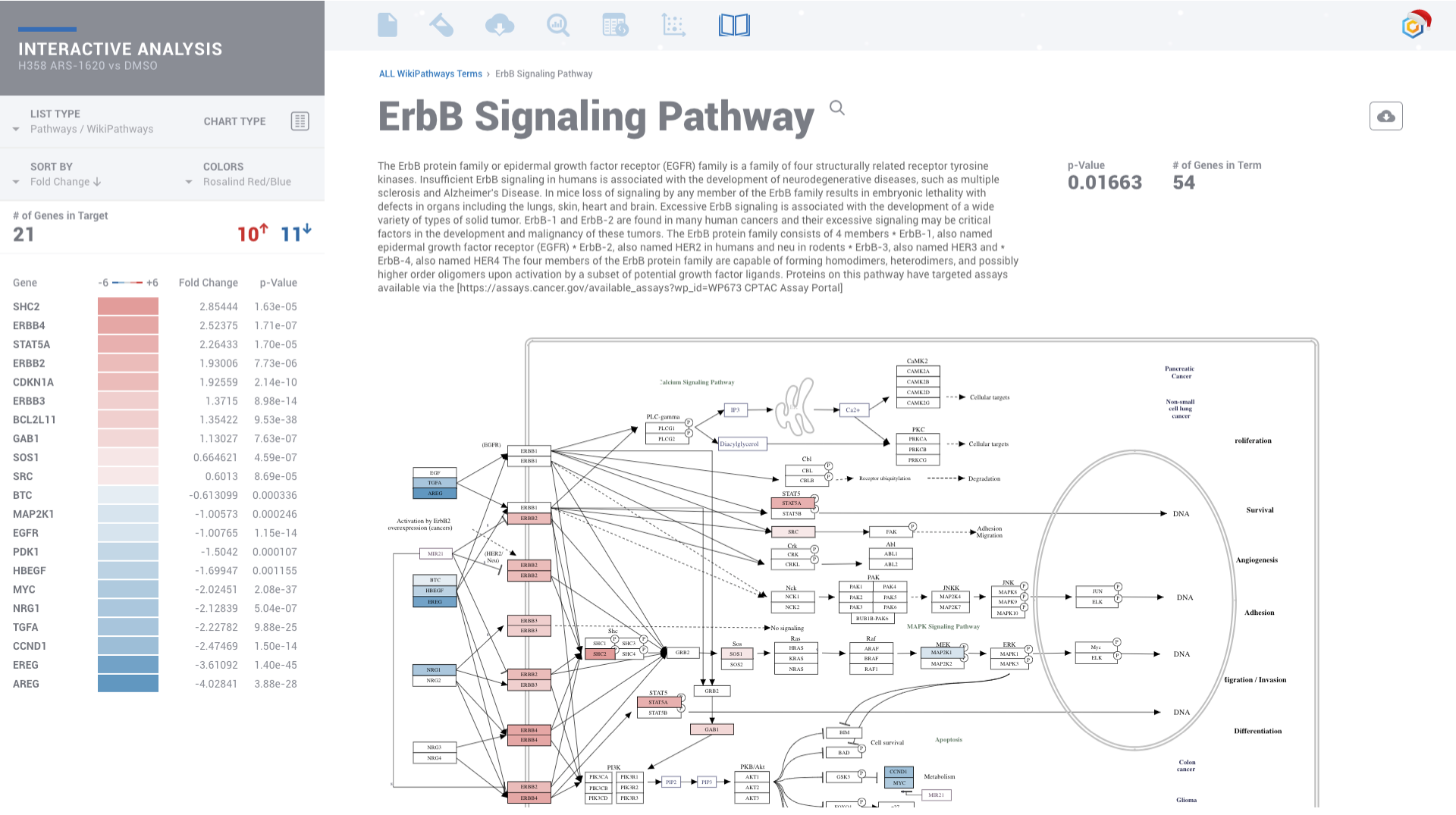
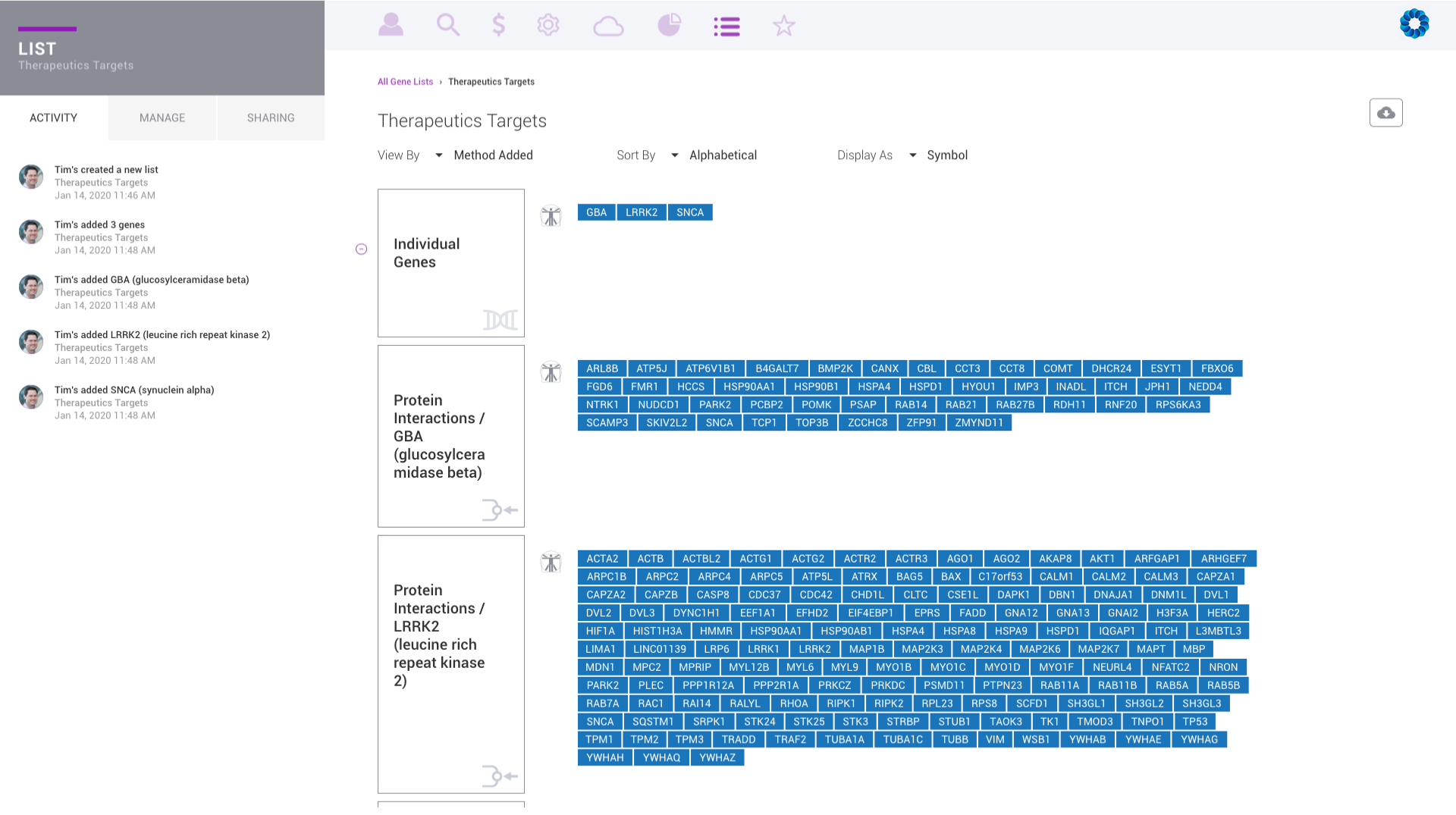
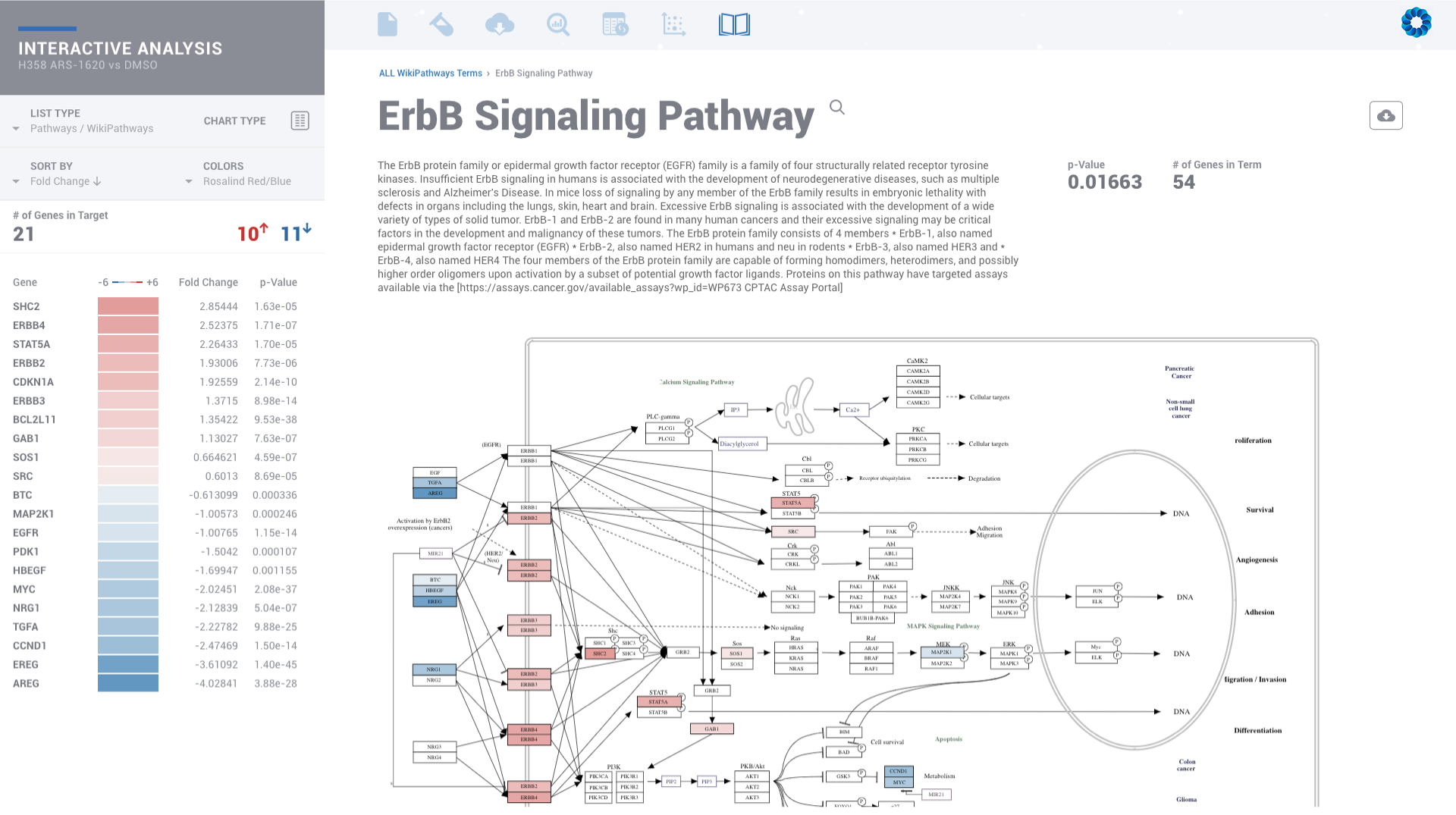
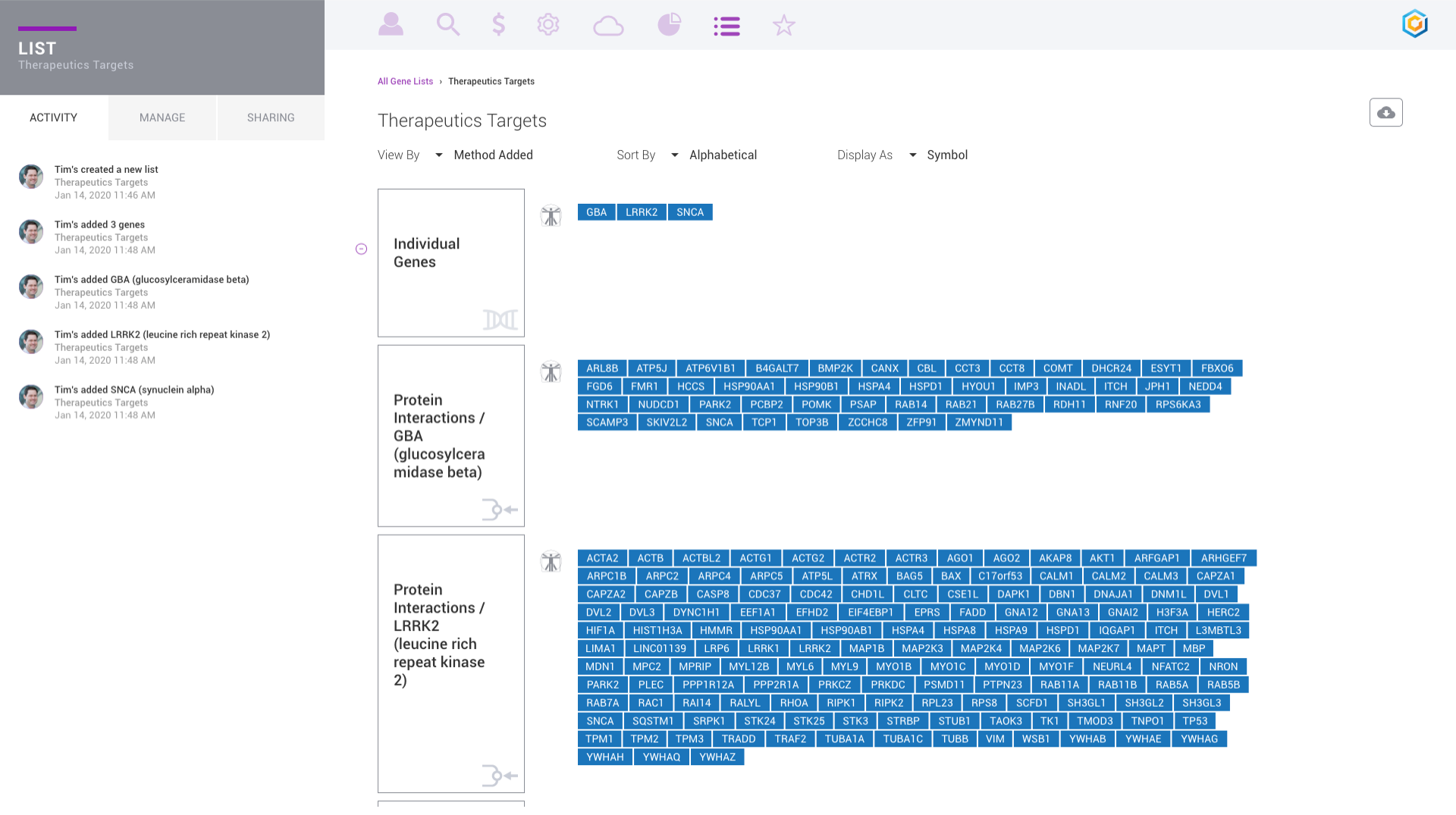
Evaluate gene signatures across nCounter experiments and public datasets. Gene signatures accelerate discovery by focusing on the genes, pathways and diseases of interest.
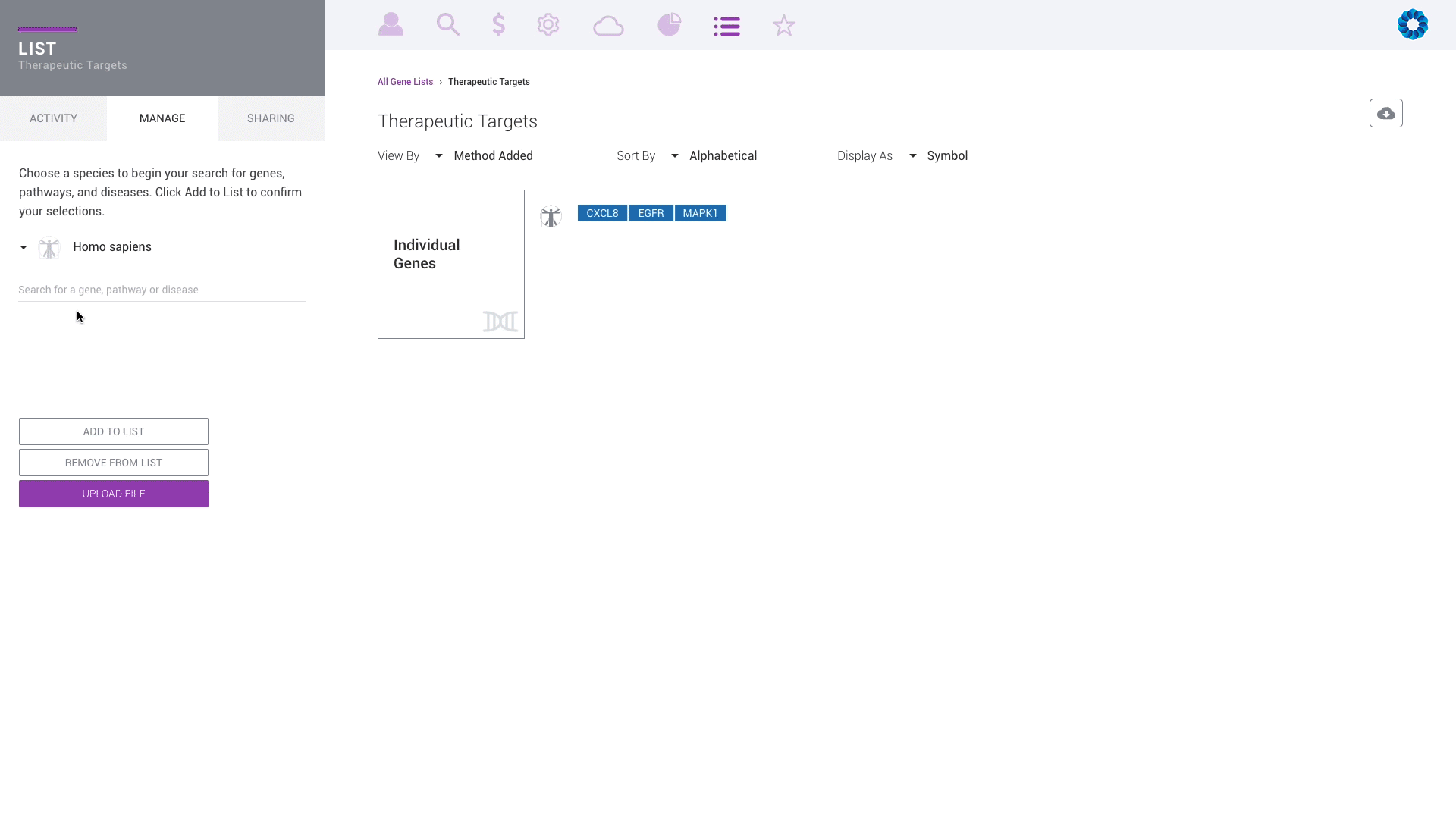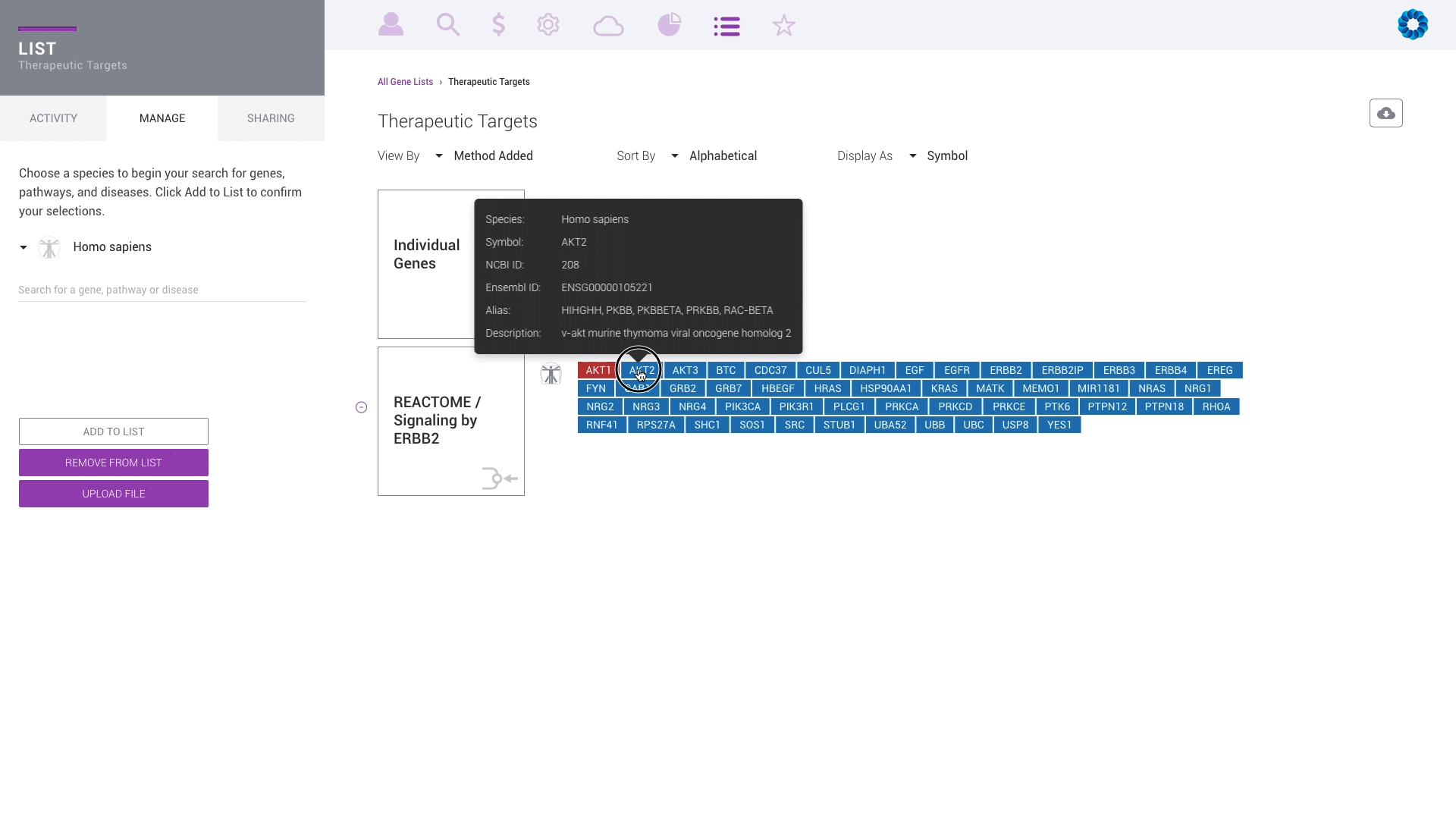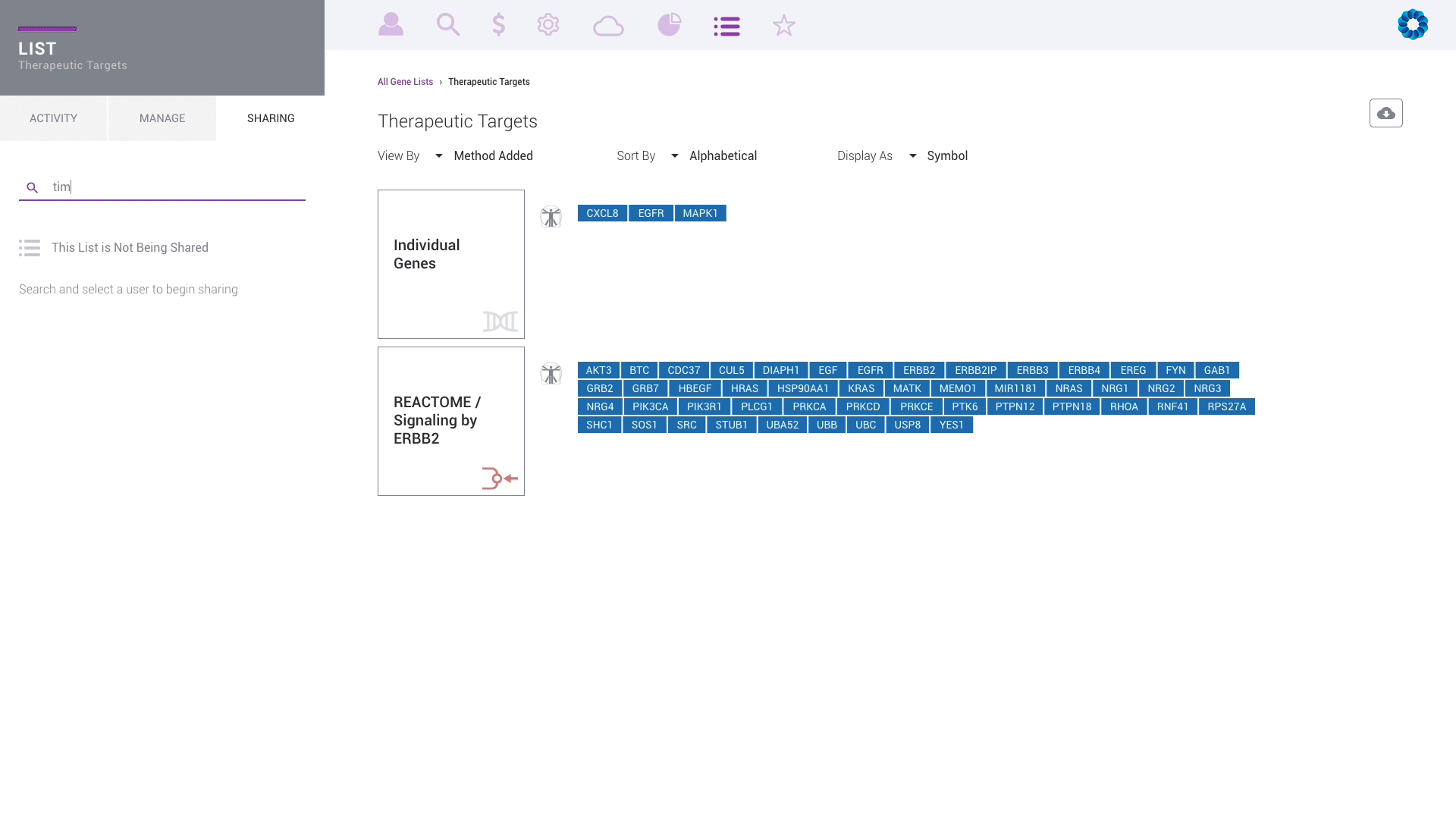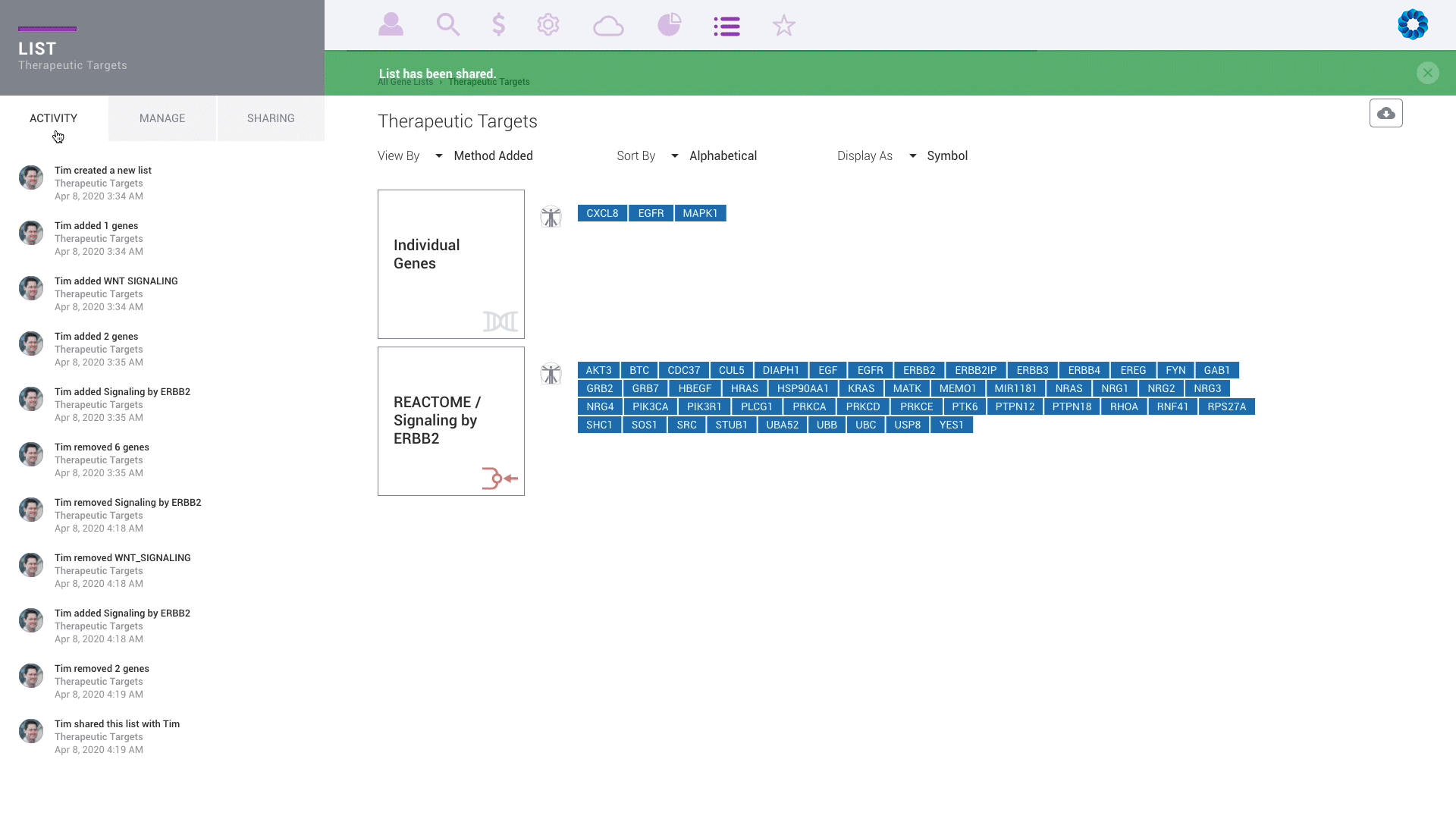
Discover, share and validate gene signatures using the Gene List Manager.
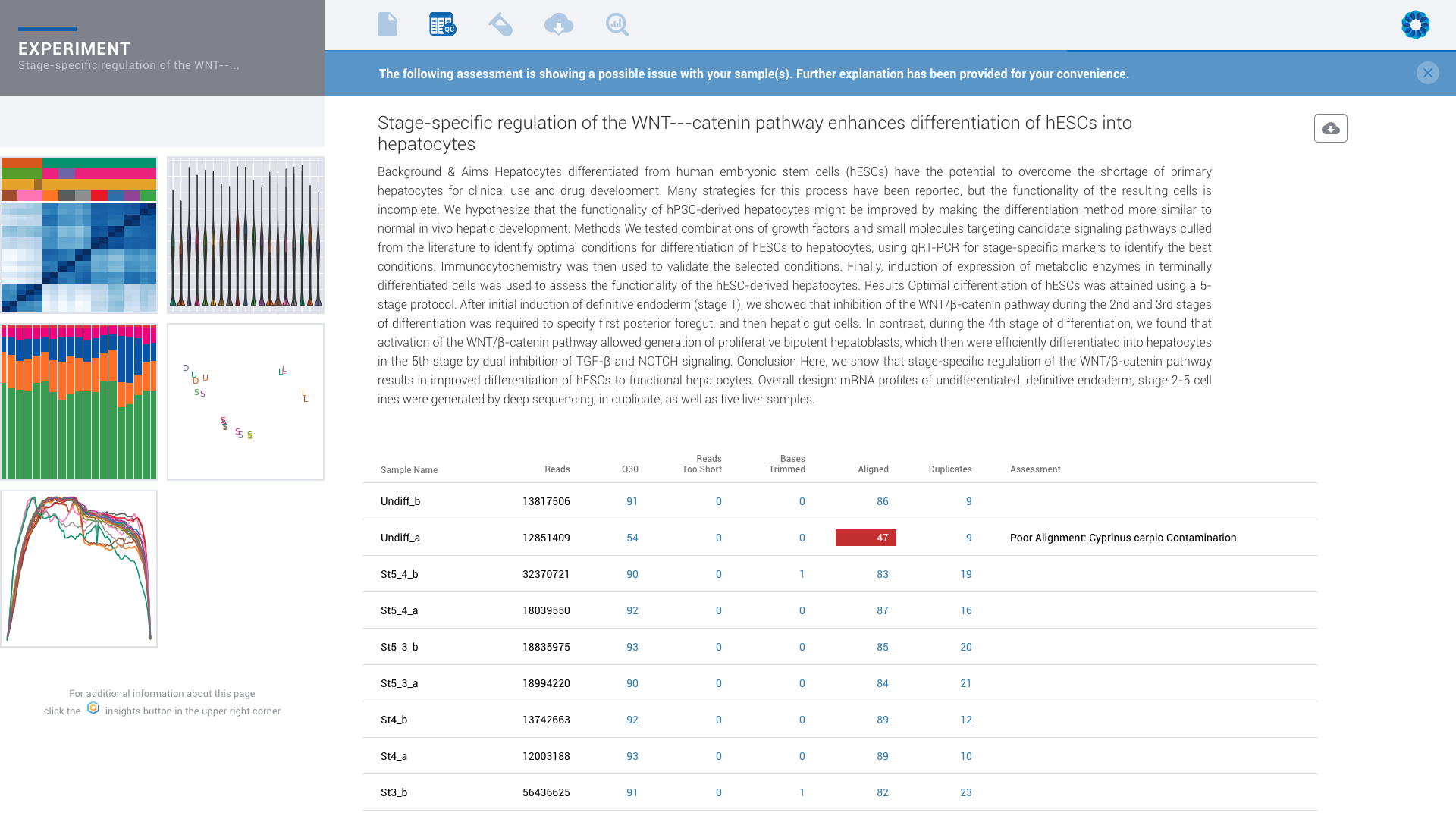

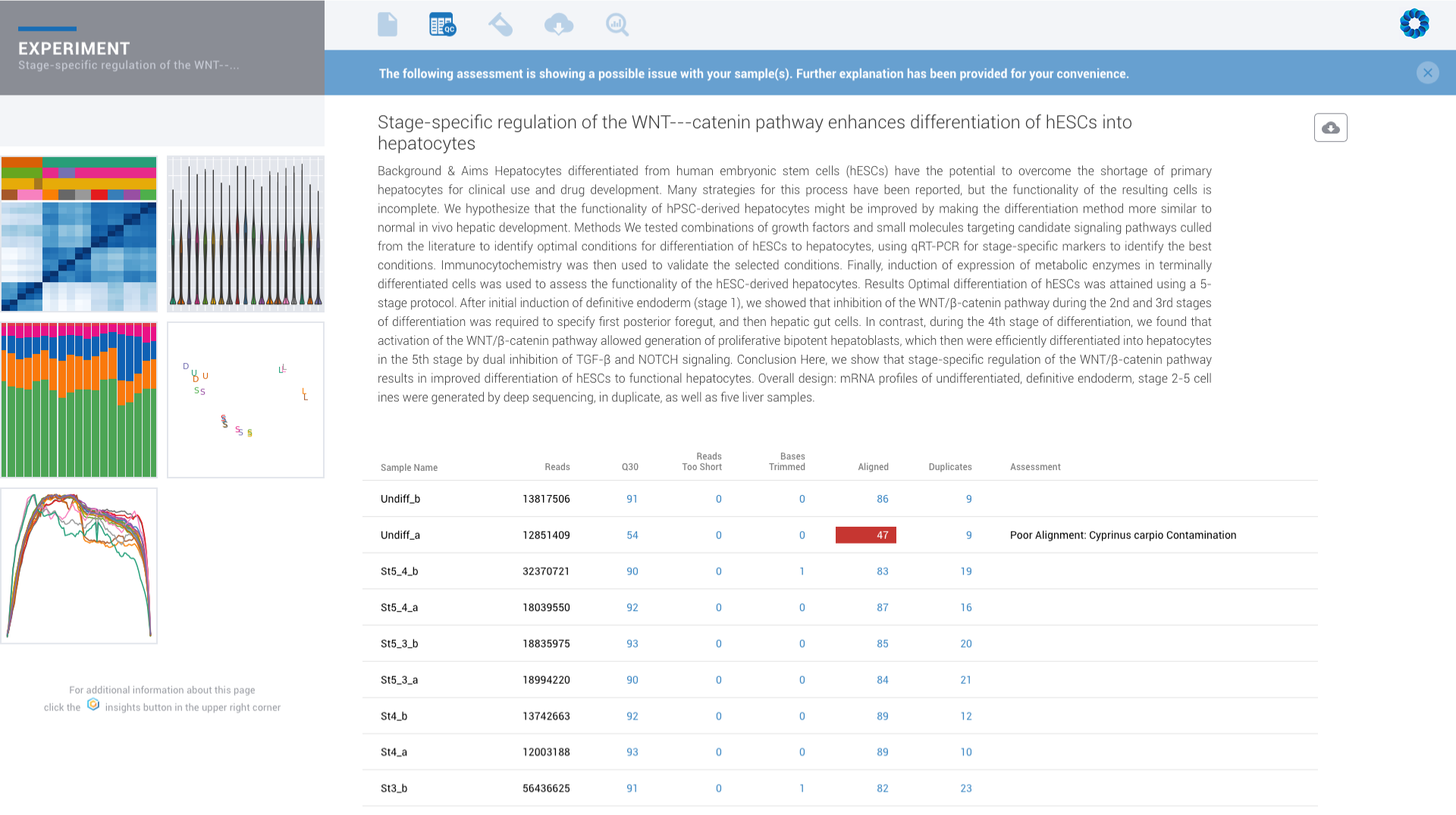
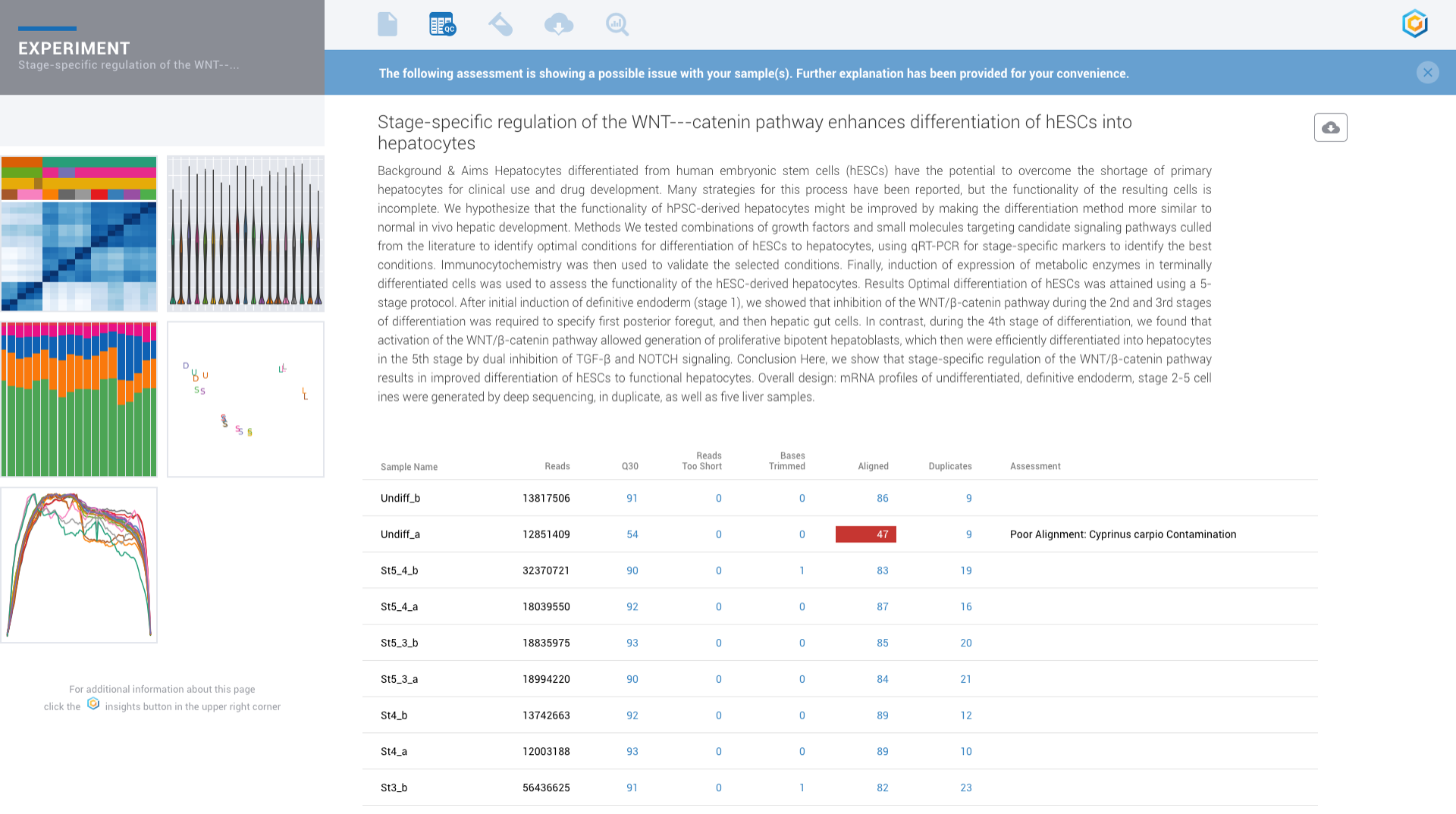
Automated contamination detection helps to identify data concerns before you invest hours into trying to diagnose results.
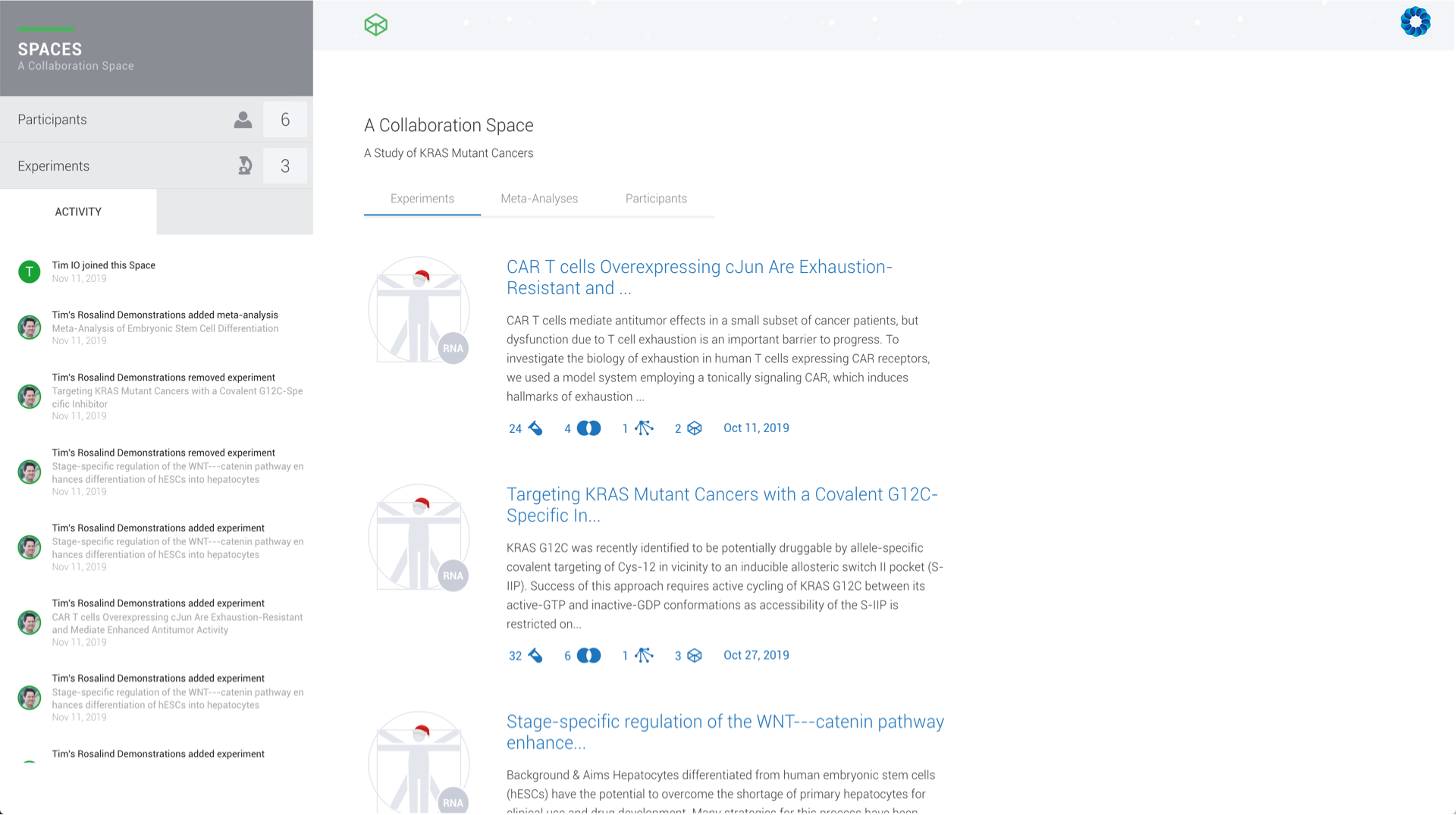
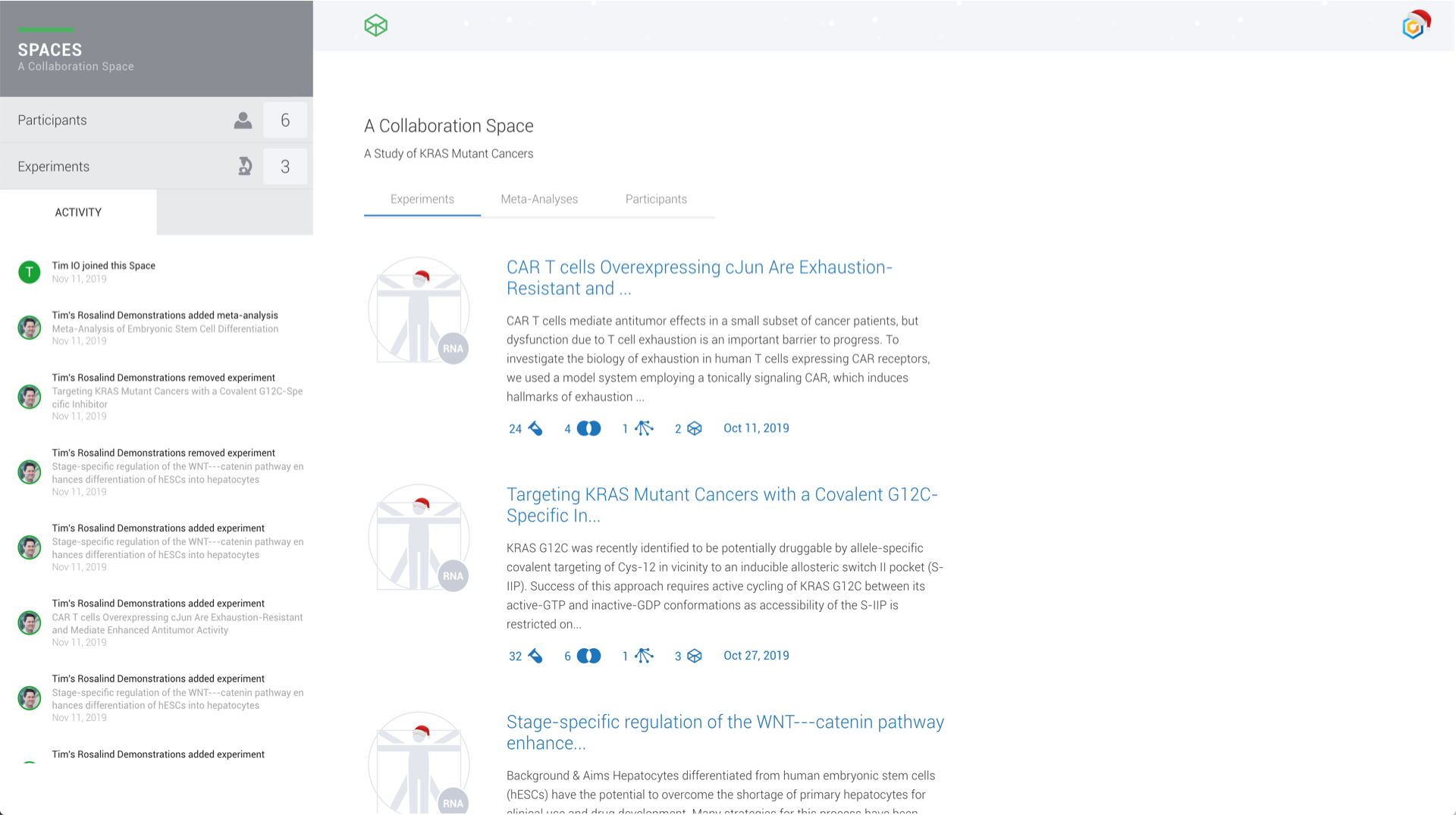
Sharing experiments and your insights with your project team and collaborators should not require offline, static screen captures or prints.
Every change is instantly available to each participant any where in the world with an audit trail reported on the activity feed.
Consistent, global collaboration on genomic data accelerates discovery and eliminates unnecessary complexity unifying your scientific expertise everywhere in the world.
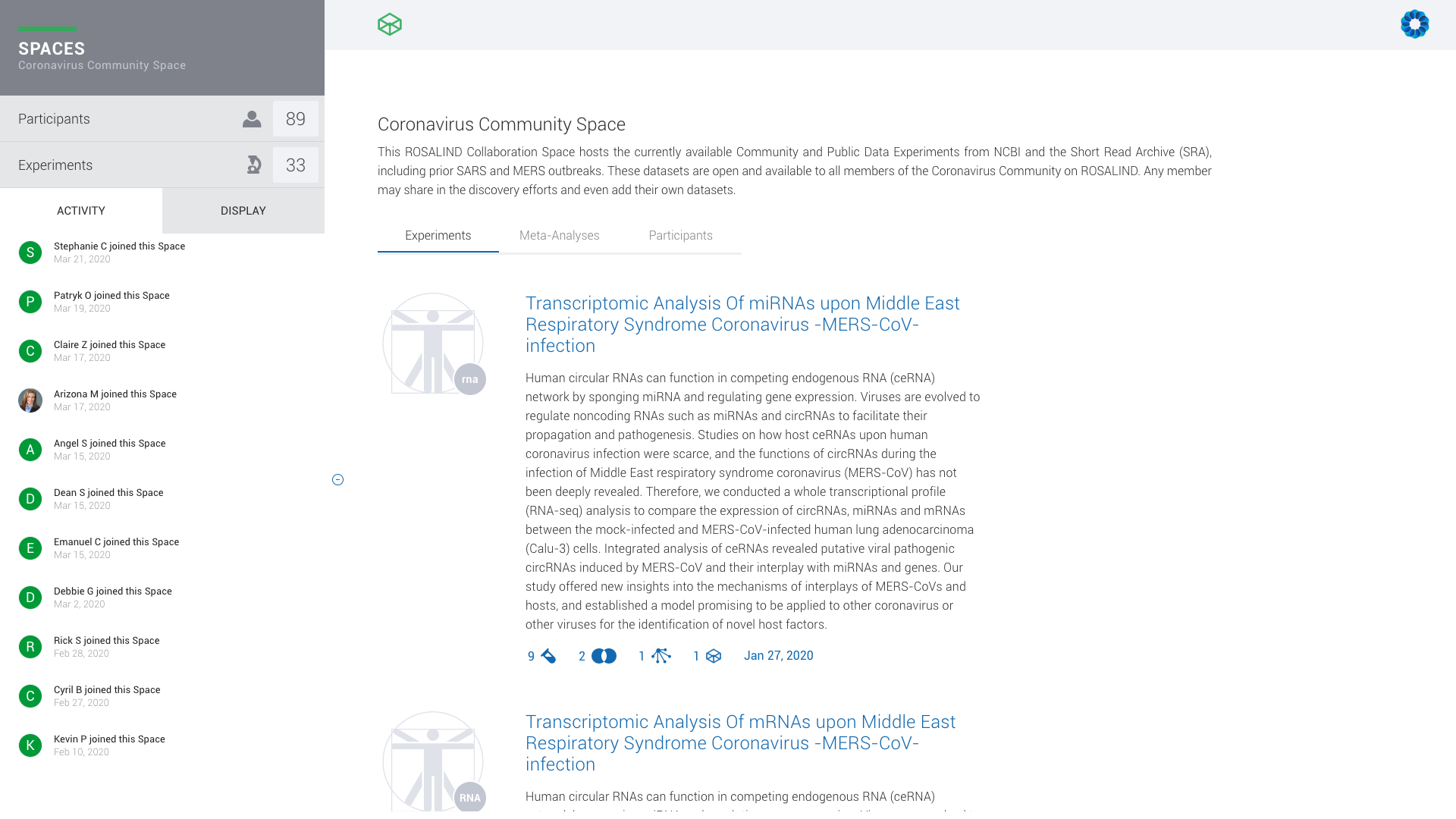


ROSALIND Collaboration Spaces connects researchers within a virtual meeting room
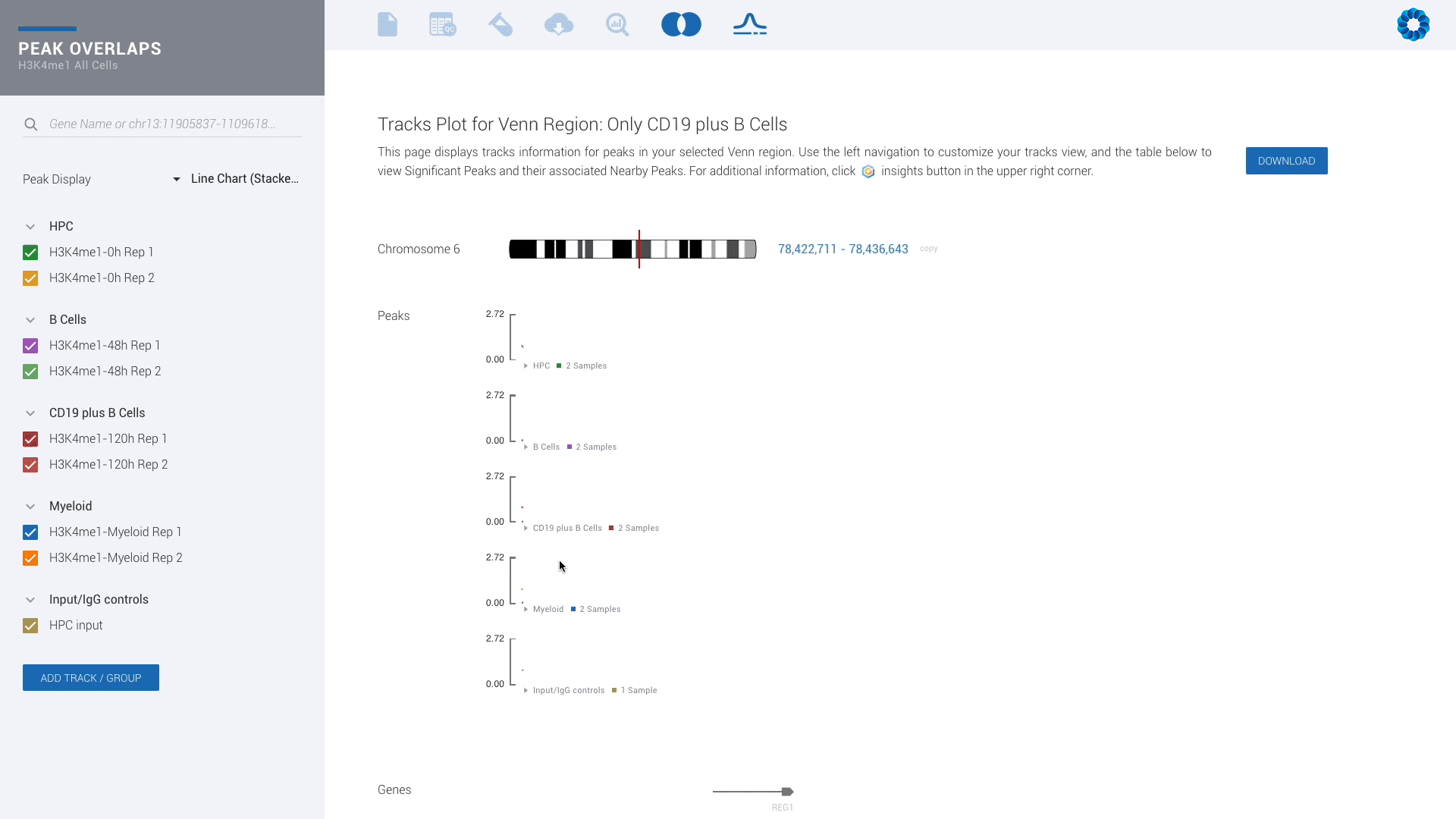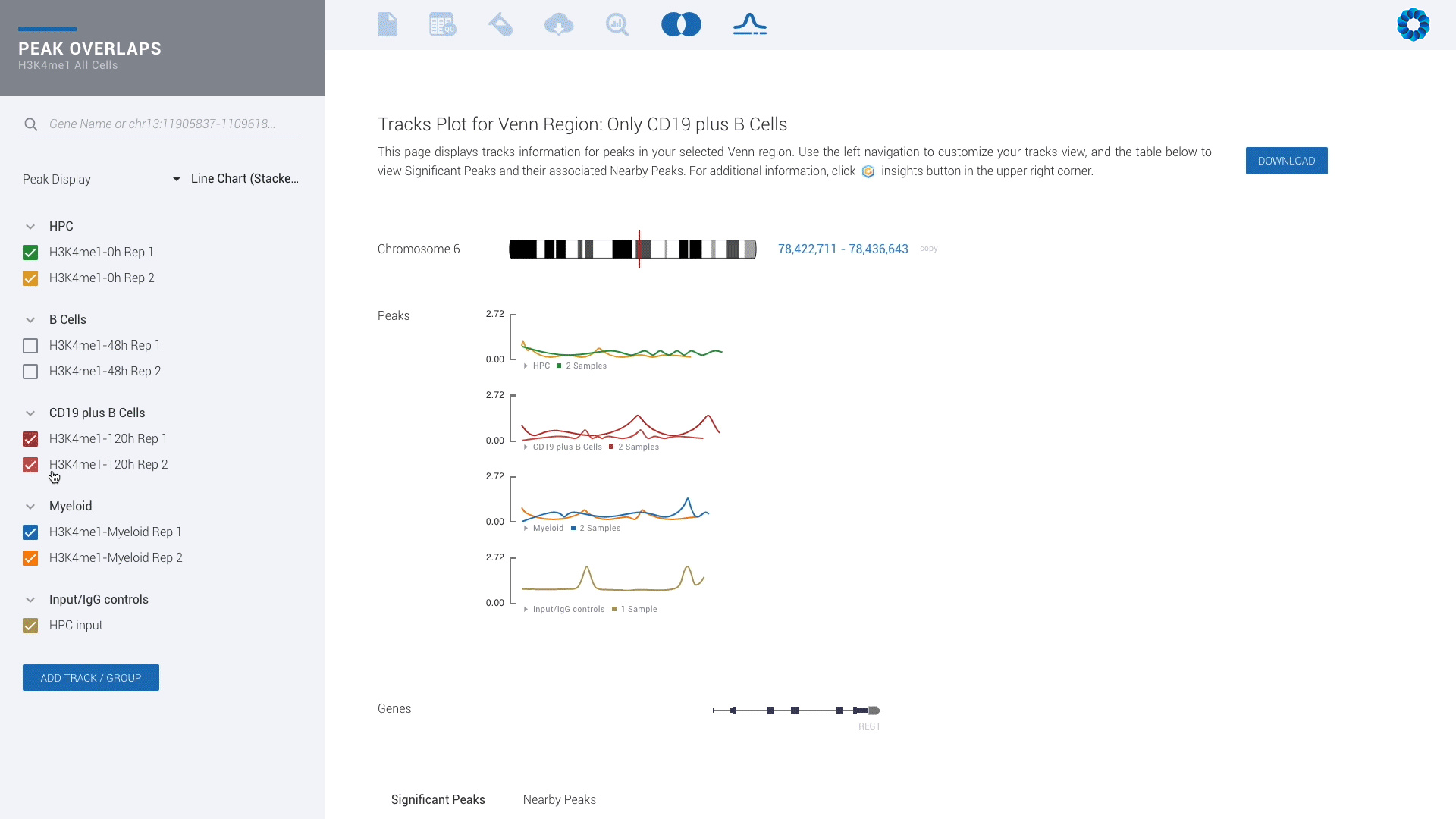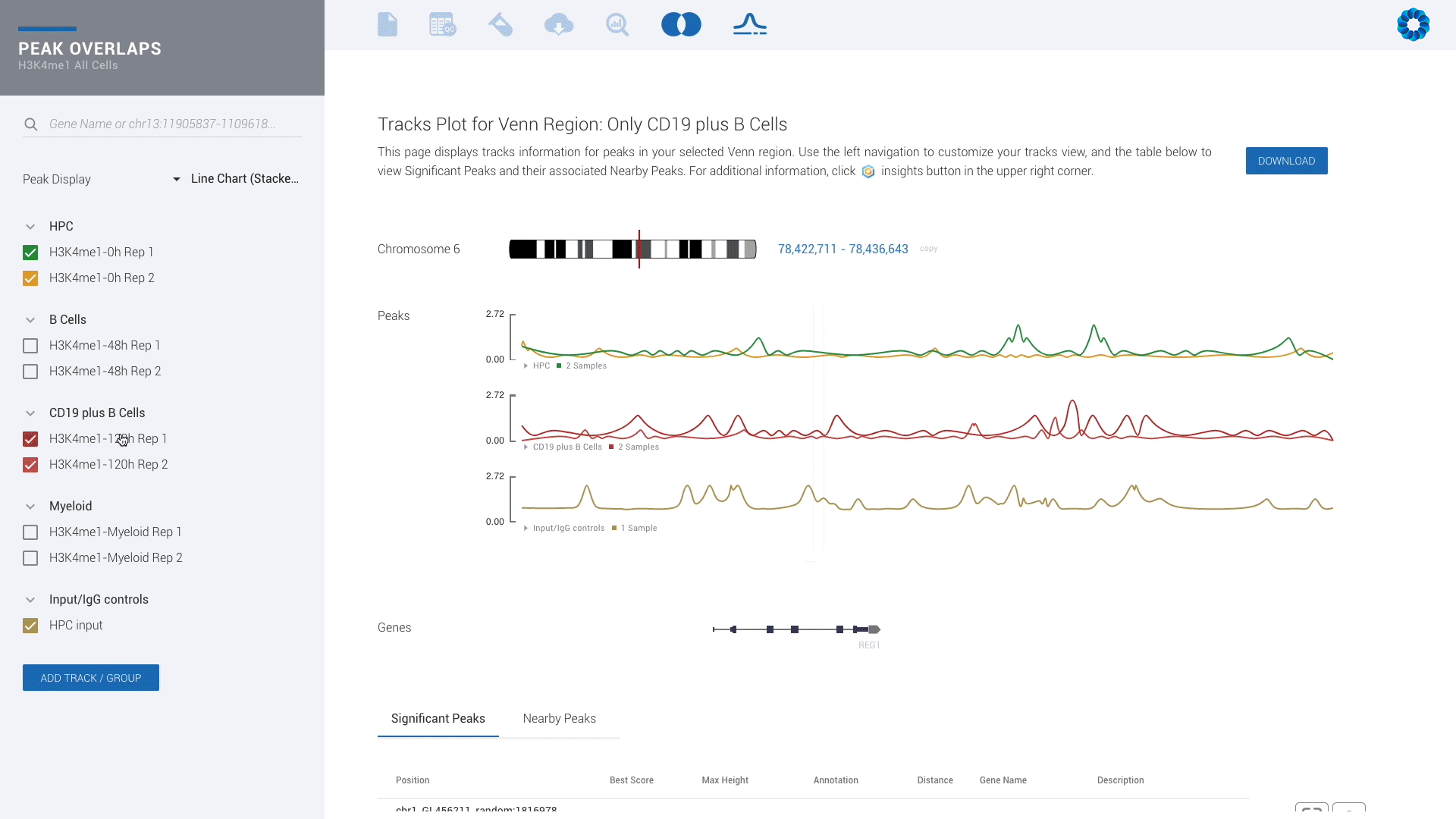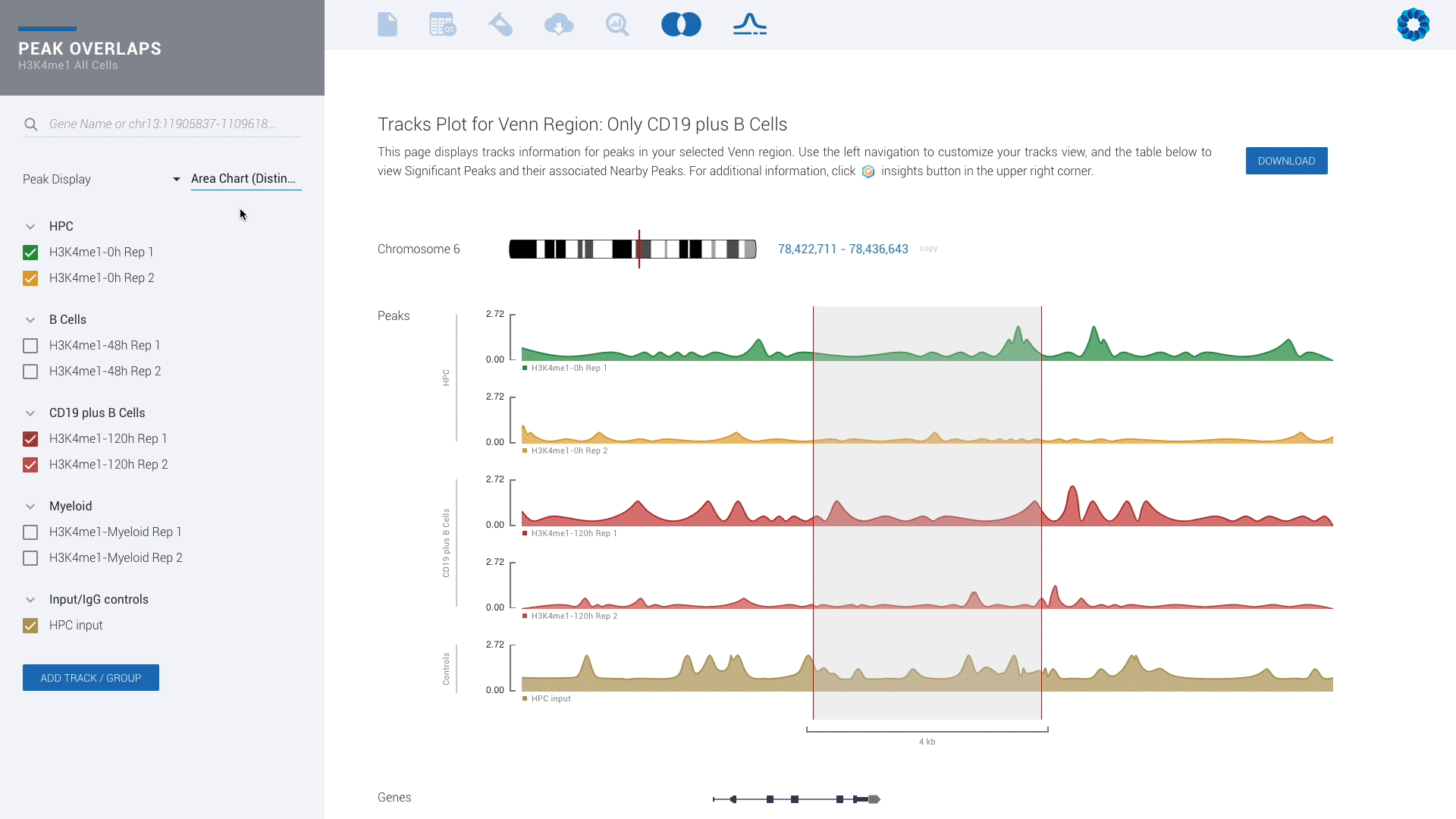
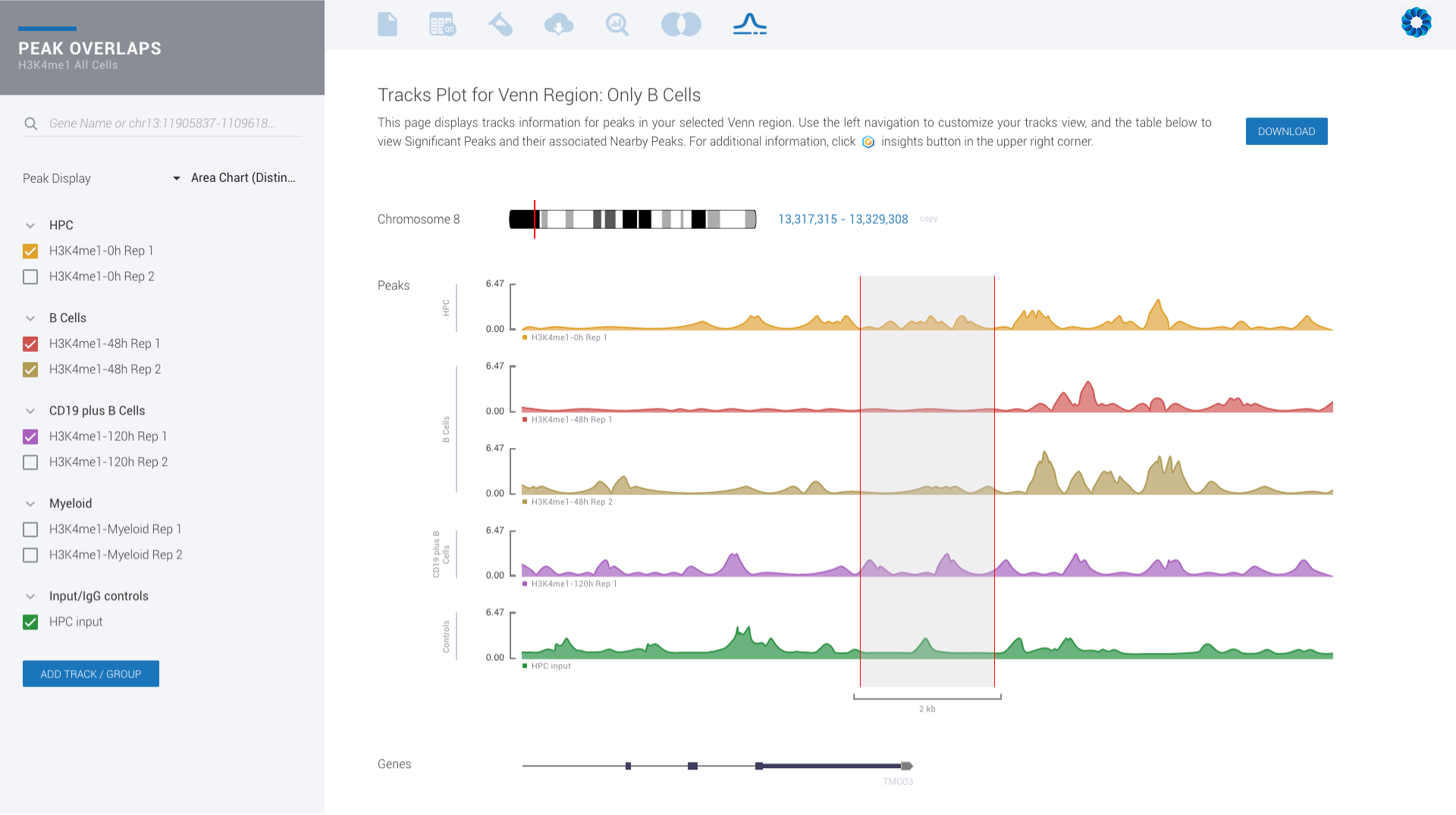
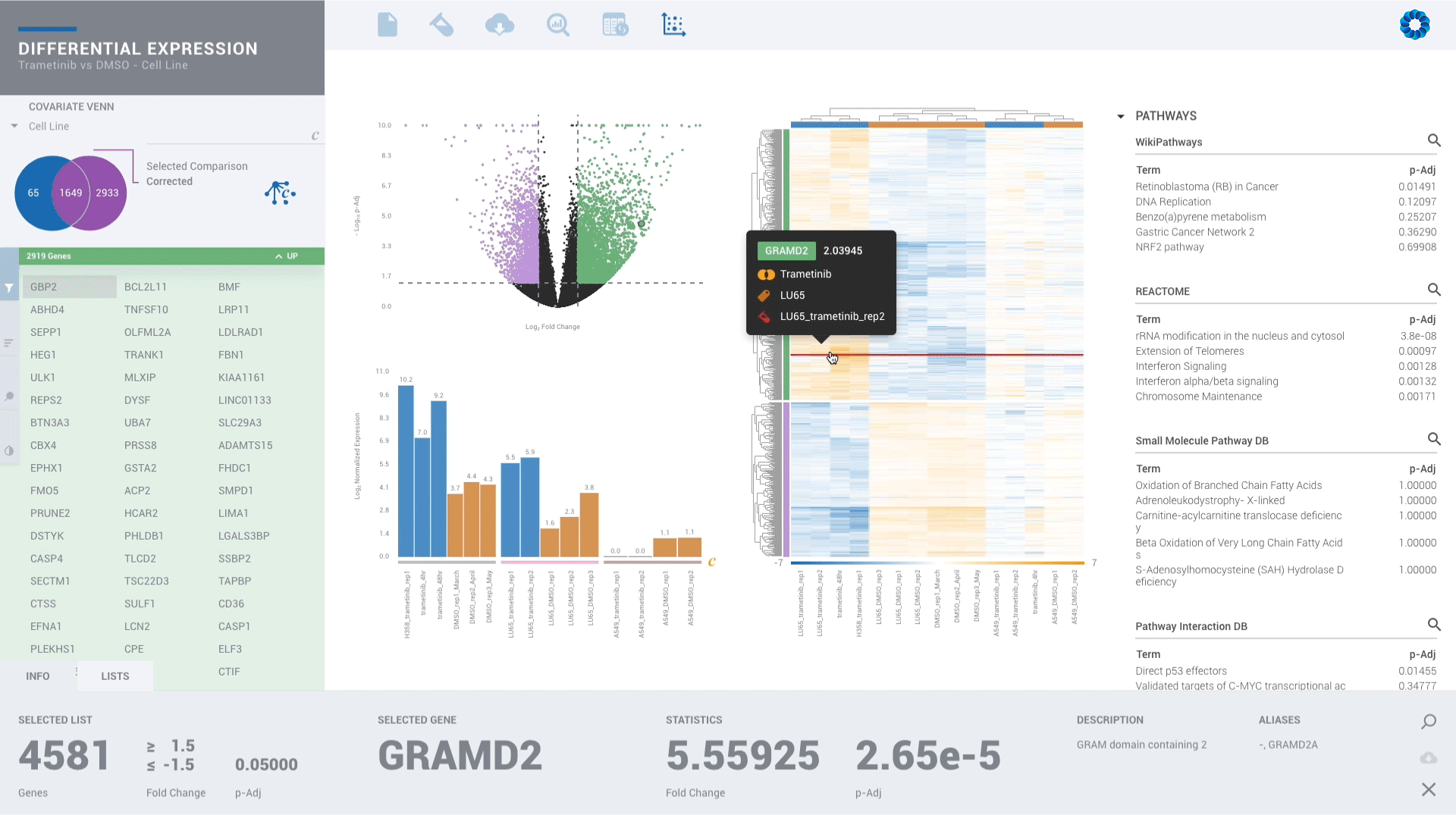
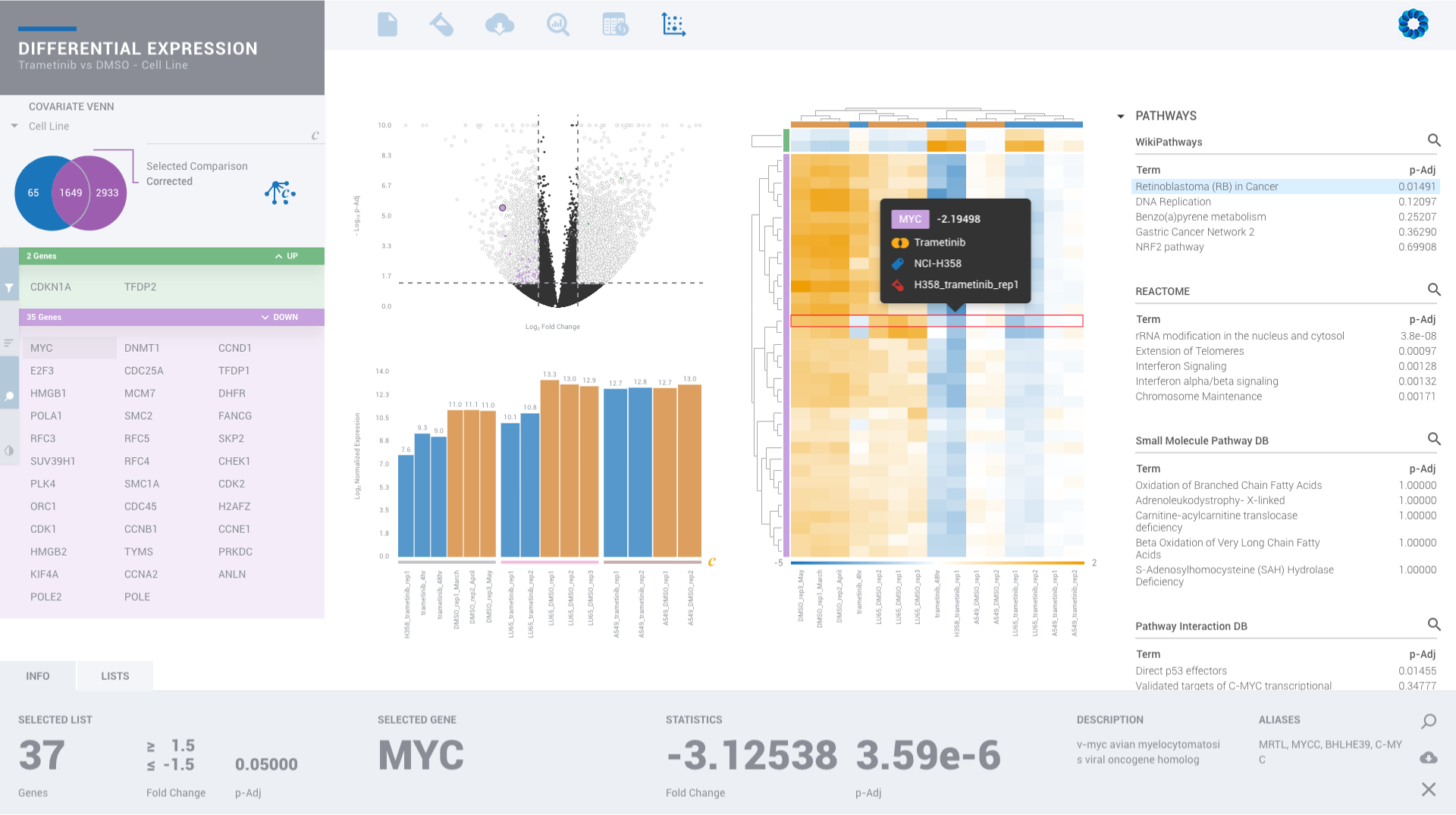
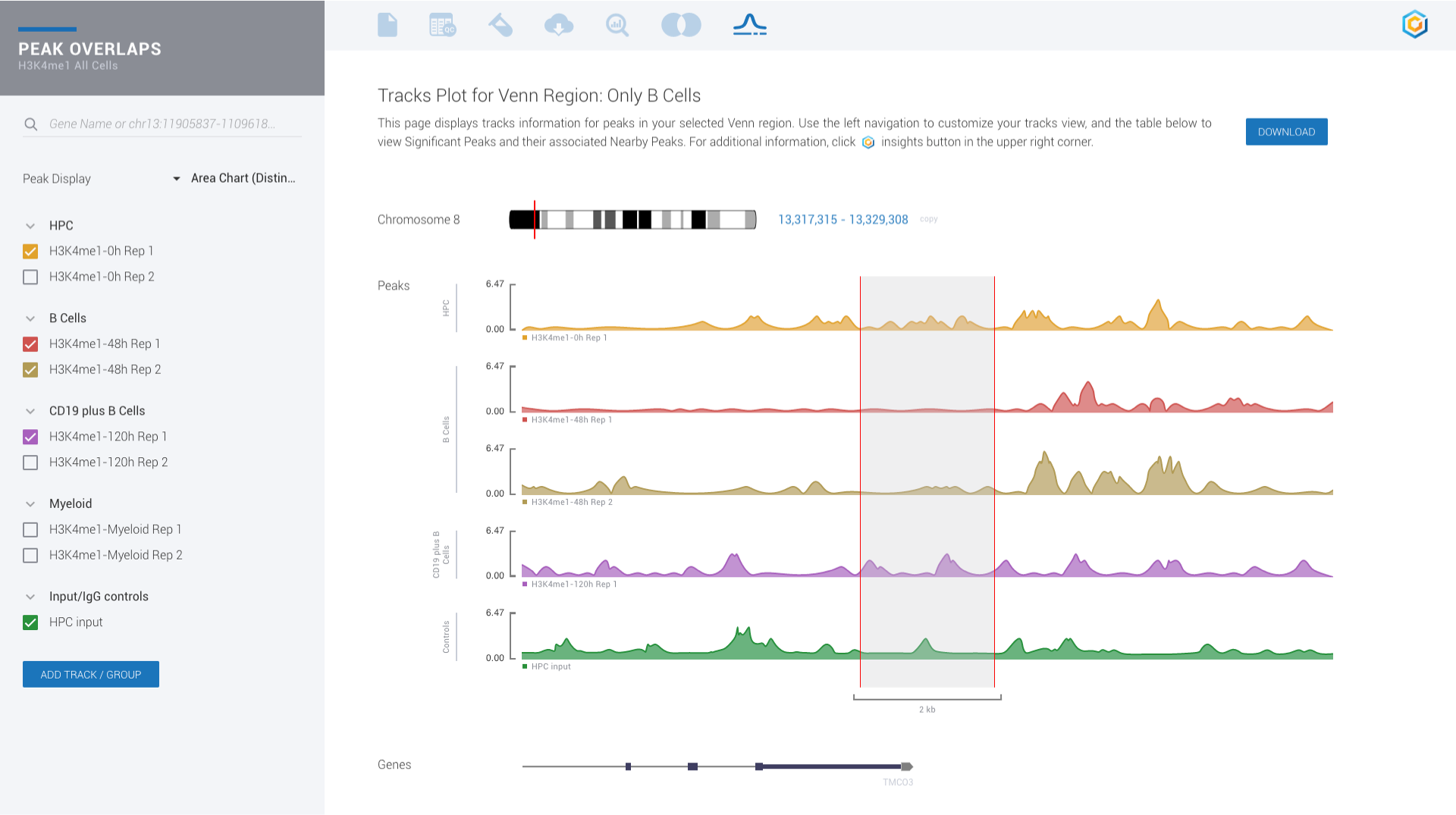
Ever seen a genome browser look this good? There is simply no reason to settle for less.
Upgrade for access to all pipelines in Gene Expression, Gene Regulation, Chromatin Accessiblity and Protein Binding to visually experience interactive plots and interpretation, rather than eye-straining spreadsheets.






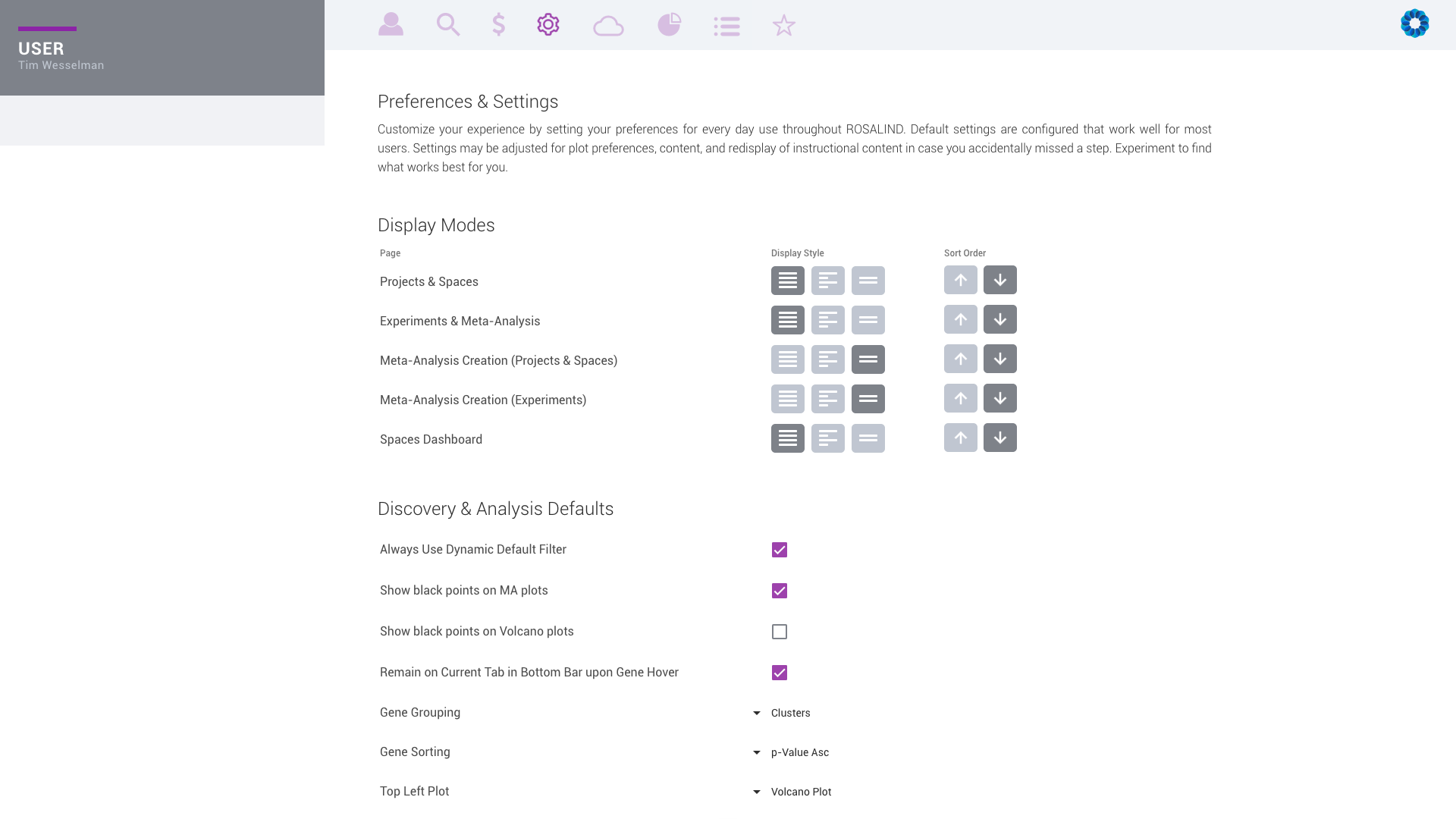
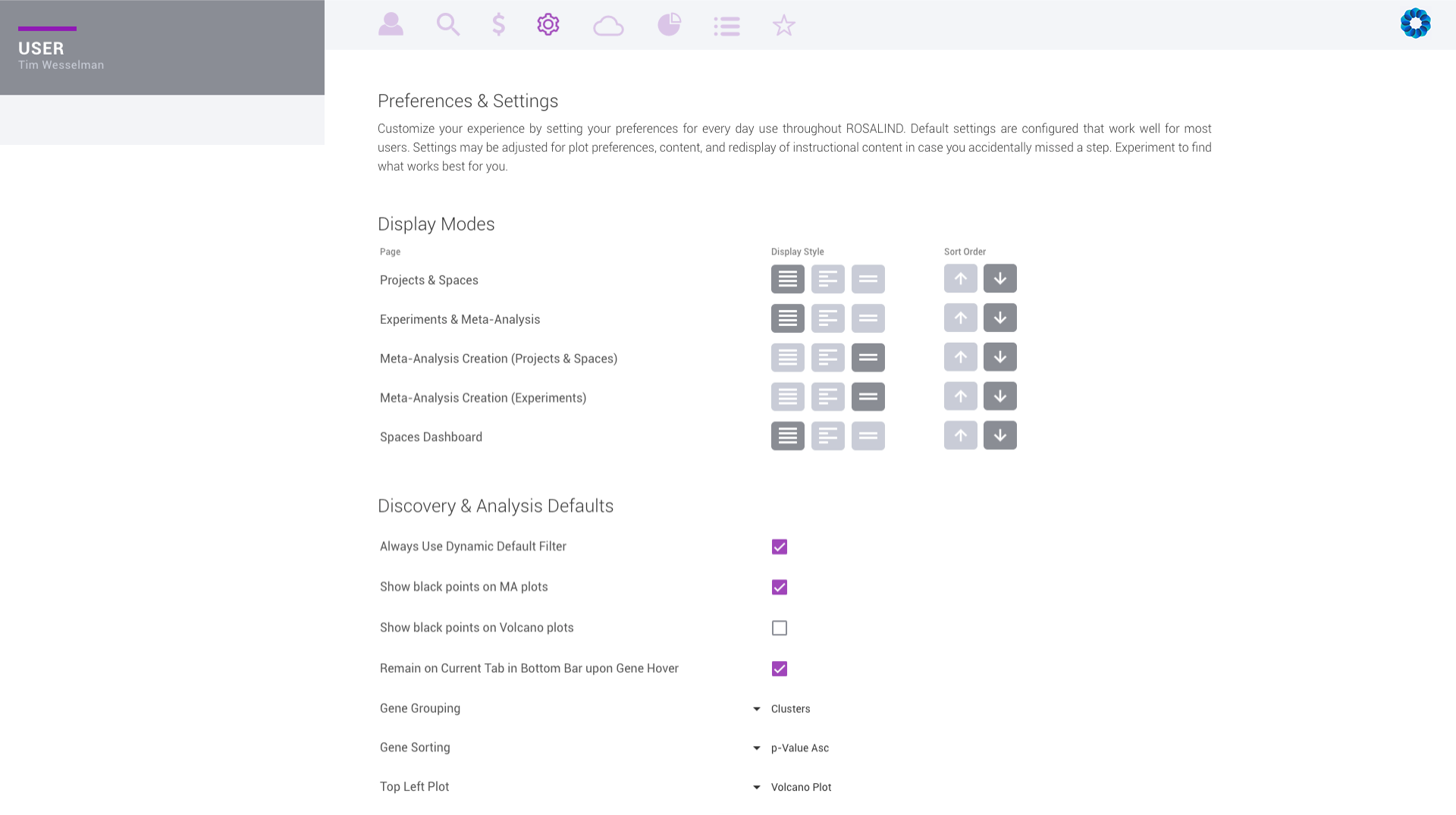
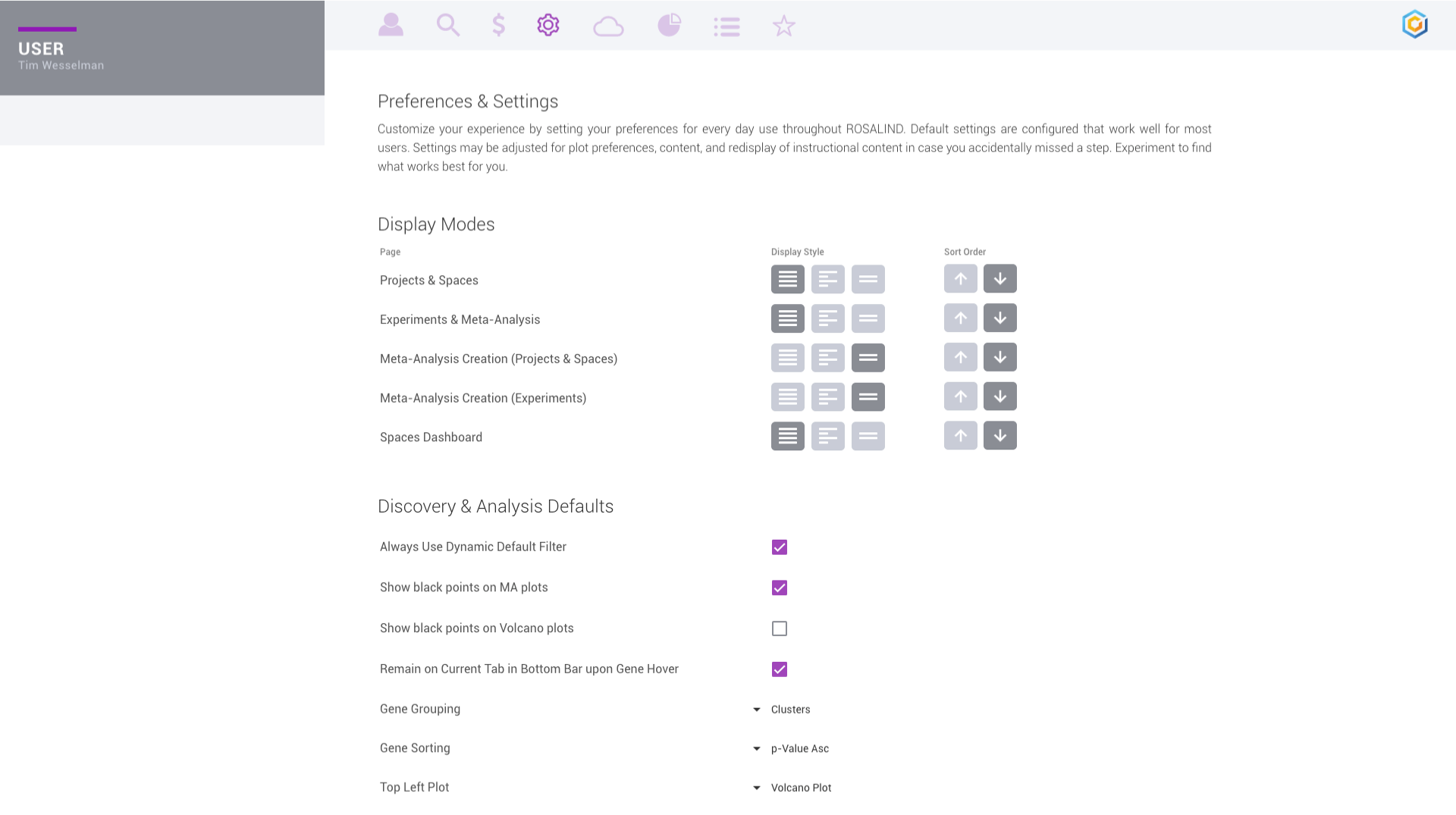
Customize your ROSALIND experience by setting personal preferences for everyday use.
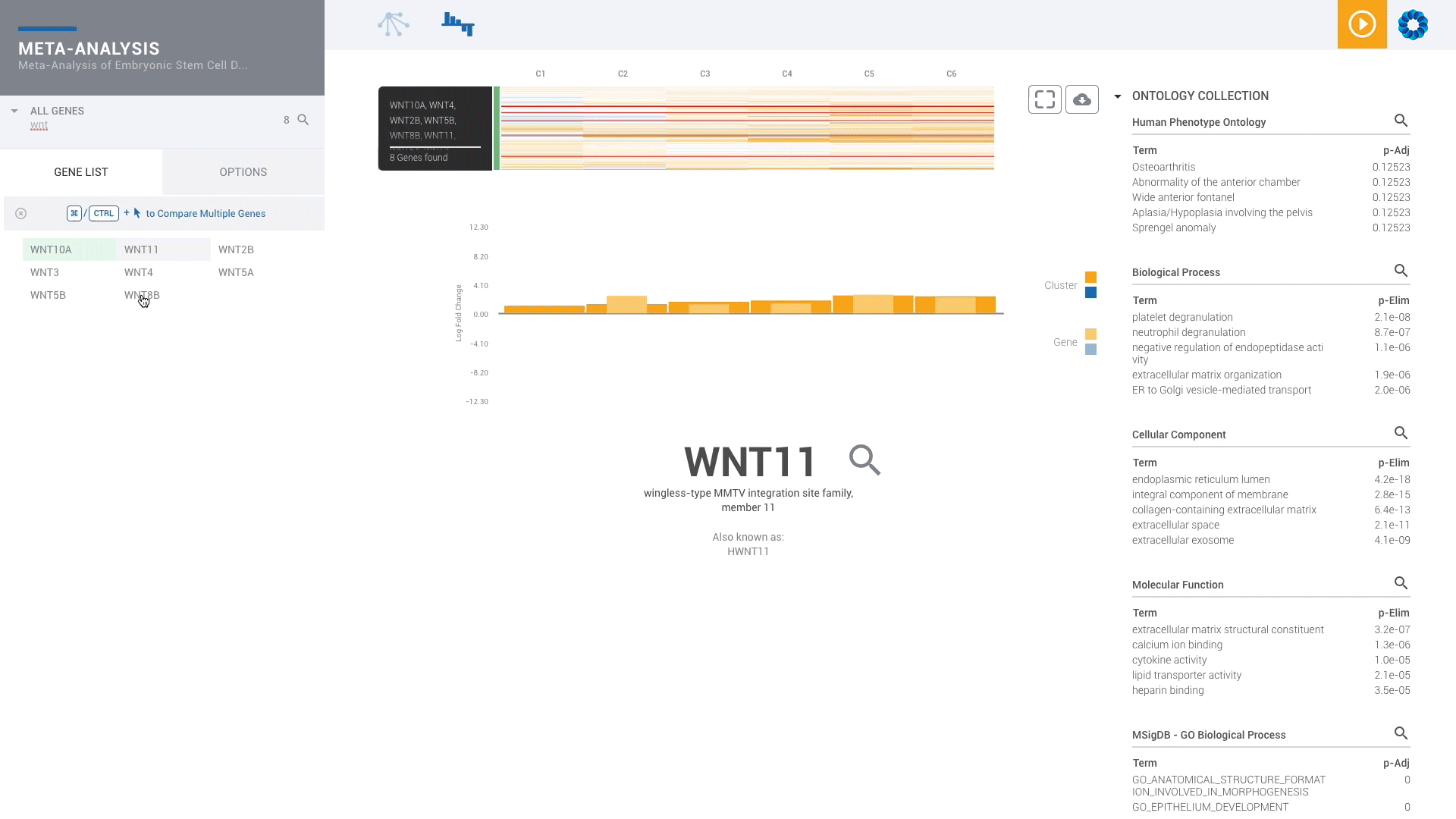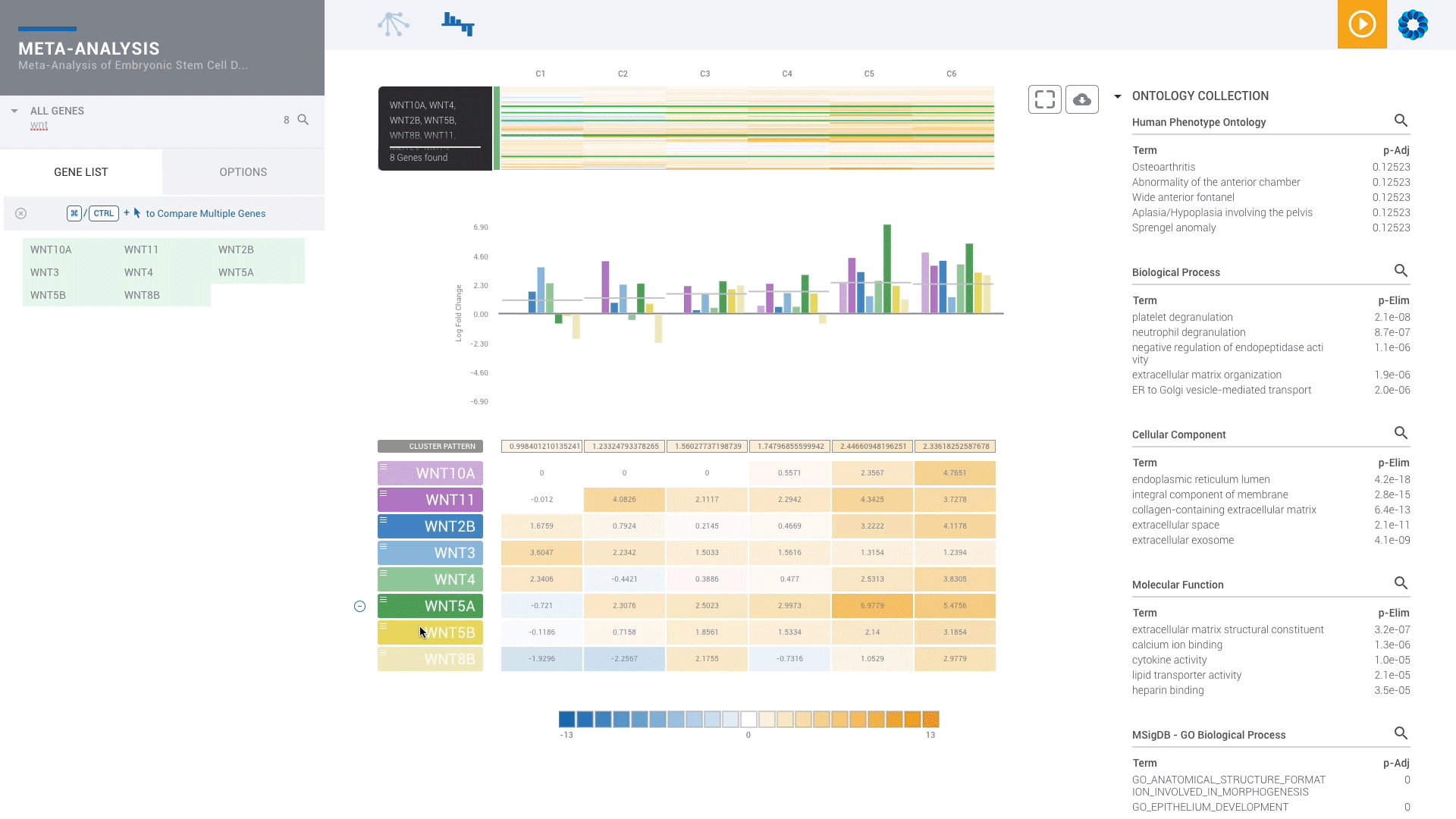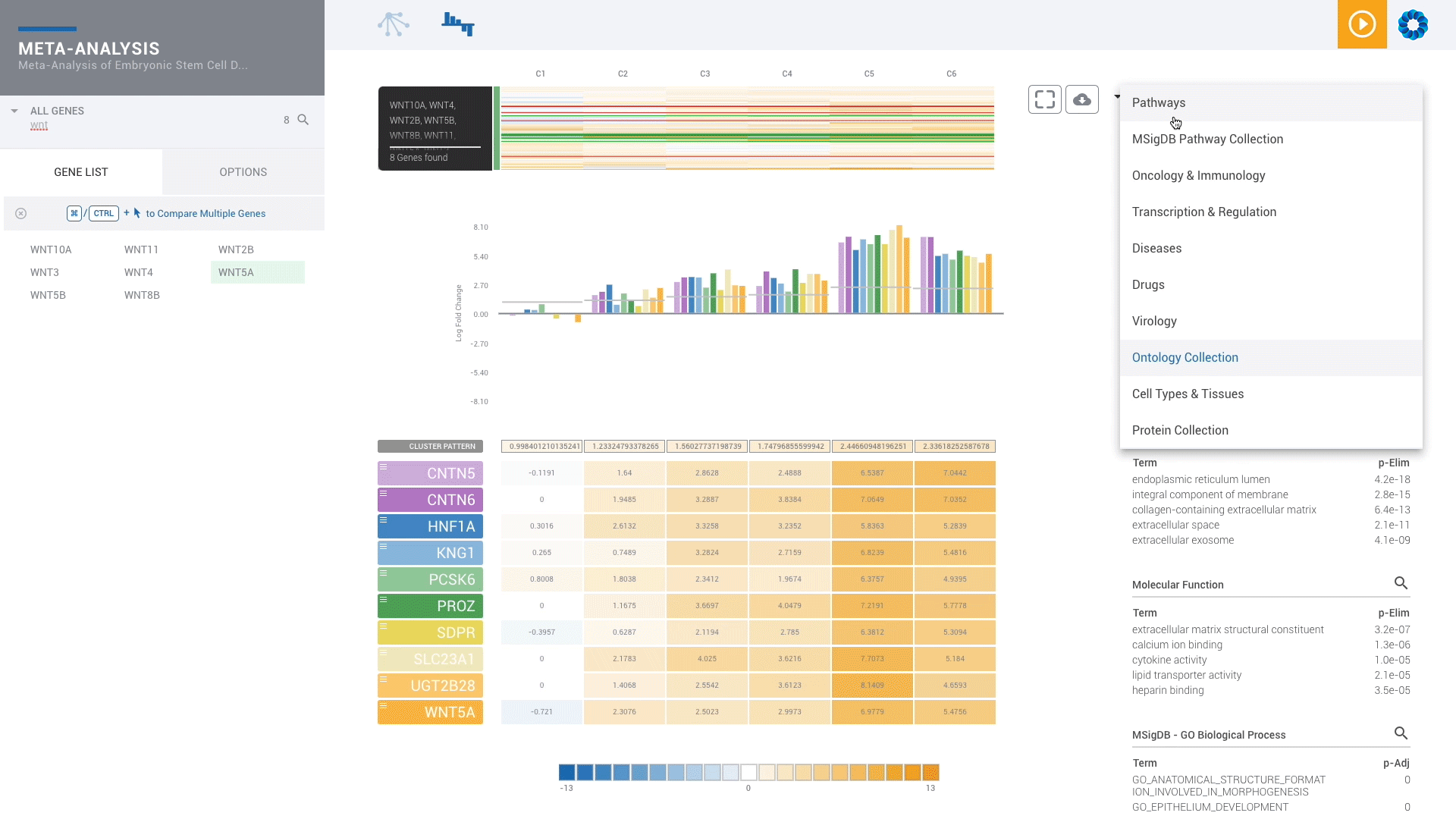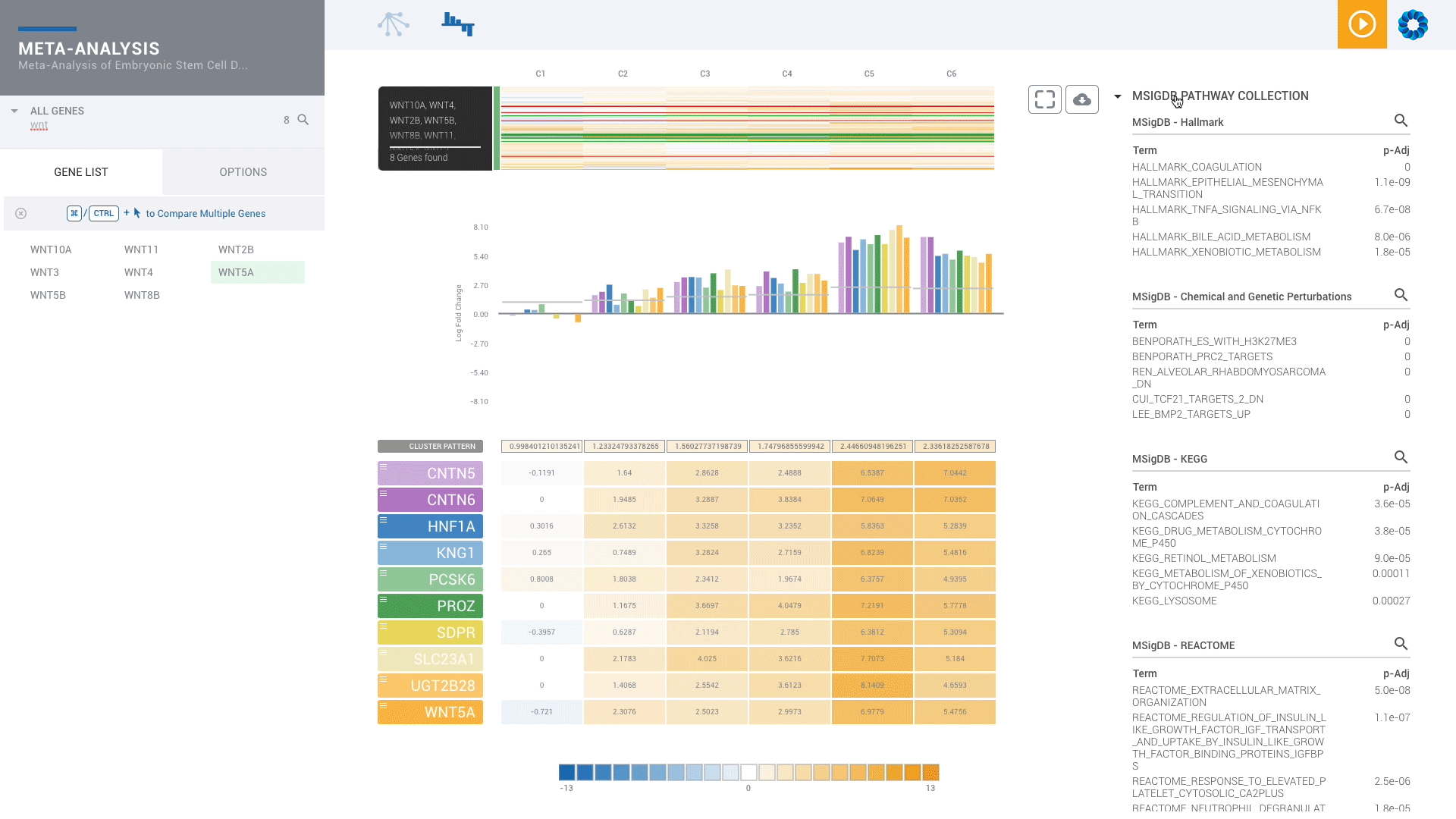
Scientists of every skill level benefit from ROSALIND since no programming or bioinformatics skills are required. With powerful downstream analysis and real-time collaboration, ROSALIND is the platform to empower your scientists and accelerate your discoveries.

Now available free of charge to all NanoString users for 1 year!
 Learn how ROSALIND can transform your nCounter analyses and collaboration
Easy step-by-step walkthrough to complete your first experiment in under 5 minutes
Gain access to new capabilities and work closely with Rosalind & NanoString experts
Learn how ROSALIND can transform your nCounter analyses and collaboration
Easy step-by-step walkthrough to complete your first experiment in under 5 minutes
Gain access to new capabilities and work closely with Rosalind & NanoString experts